Yolo는 Object Detection에 쓰이는 모델로써, 그 밖에도 segmentation, pose estimation? 등이 있다고 한다.
Object Detection은 이미지 내에서 object가 있다고 판단되면 각 객체의 위치와 클래스 정보를 알려주는 역할을 한다.
Yolo 모델을 공부하기에 앞서,
객체 Detector는 크게 2가지로 나뉘는데, 바로 1-stage Detector와 2-stage Detector이다.
1-stage Detector의 경우 Regional proposal과 Classification이 동시에 이루어진다!
2-stage Detector의 경우 Regional proposal과 Classification이 순차적으로 이루어진다!
먼저 Regional proposal과 Classification에 대해서 알아야하는데,
Regional proposal은 직역하면 "지역 제안"이며 얼핏 드는 생각은 이미지 중에서 검출할 영역을 탐색하는 것?이다.
정확하게는 이미지에서 유사한 색,텍스쳐를 가지고 있는 부분들을 보고 어떠한 객체가 있을 것이라 추정하는 영역을 찾는 것이다. 또한 이방식은 class는 고려하지 않고, object가 있을것 같다 생각하면 모두 잡아낸다는 특징이 있어, 매우 빠르지만 정확도는 비교적 낮다고 평가되는 방식이다.
Regional proposal 방식에는 대표적으로 두 가지가 있으며, 이름만 알고 가자.
1. Sliding Window
2. Selective Search
따라서 2-stage Detector는 순차적으로 진행된다고 하였으며, 아래 그림과 같다.
2-stage Detector을 사용하는 모델로는 R-CNN등 이 있다.
1-stage Detector는 Regional proposal과 Classification이 동시이루어진다고 하였다.
이것이 Yolo 모델이며 아래 그림과 같다.
YOlo에서는 Anchor Box라는 것을 통하여 객체를 detection하는데,
Anchor Box란 특정 값이 이미 정의된 경계 상자(bounding box)를 의미한다. (v3모델의 경우 3개의 앵커를 가진다고 한다.)
또한 앵커 박스는 K-means에 의한 데이터로부터 생성되며, 학습을통해 처음 앵커의 위치와 크기를 조금씩 조정해가며 객체를 탐지한다고 한다.
이 개념을 통해서 2-stage-Detector에서 쓰이는 Sliding window를 사용할 필요가 없게 된다.
Sliding Window는 모든 잠재적 위치에서 별도의 예측을 해야하는 계산을 해야 하는데,
즉, 모든 parameter의 경우의 수에 대해 cross-validation 결과가 가장 좋은 parameter를 고르는 방법이다.
전체 탐색 대상 구간을 어떻게 설정할지,간격은 어떻게 설정할지 등을 결정하는 데 있어 여전히 사람의 손이 필요하나
앞선 Manual Search와 비교하면 좀 더 균등하고 전역적인 탐색이 가능하다는 장점이 있다.
하지만 탐색하고자하는 hyperparameter의 개수를한 번에 여러 종류로 가져갈수록, 전체 탐색 시간이 기하급수적으로 증가한다는단점이 있다.
2. 랜덤 서치
Random Search는 Grid Search와 큰 맥락은 유사하나
탐색 대상 구간 내의 후보 hyperparameter 값들을 랜덤 샘플링을 통해 선정한다는 점이 다르다.
Random Search는 Grid Search에 비해 불필요한 반복 수행 횟수를 대폭 줄이면서, 동시에정해진 간격(grid) 사이에 위치한 값들에 대해서도확률적으로 탐색이 가능하므로, 최적 값을 더빨리찾을 수 있는 것으로 알려져 있다.
즉, 랜덤서치는 모든 grid를 전부 찾는 대신, 랜덤하게 일부의 파라미터 들만 관측한 후, 그 중에서 가장 좋은 파라미터를 고른다.
그리드 서치는 중요한/ 안중요한 파라미터들을 동일하게 관측해야하기 때문에, 정작 중요한 파라미터를 다양하게 시도해볼 수 있는 기회가 적지만
랜덤서치는 grid로 제한되지 않기 때문에 확률적으로 중요 변수들을 더 살펴볼 수 있는 기회를 받게 됩니다.
그럼에도 불구하고, 랜덤 서치에서도 '여전히 약간의불필요한 탐색을 반복하는 것 같다’는 느낌을 지우기 어려우실 것이라고 생각합니다.
왜냐하면 그리드 서치와 랜덤 서치 모두, 바로 다음 번 시도할 후보 hyperparameter 값을 선정하는 과정에서, 이전까지의 조사 과정에서 얻어진 하이퍼파라미터 값들의 성능 결과에 대한‘사전 지식’이 전혀 반영되어 있지 않기때문입니다.
매 회 새로운 하이퍼 파라미터 값에 대한 조사를 수행할 시 ‘사전 지식’을 충분히 반영하면서, 동시에 전체적인 탐색 과정을 체계적으로 수행할 수 있는 방법론으로, 베이지안 옵티마이저를 들 수 있습니다.
3. 베이지안 옵티마이저
Bayesian Optimization은 어느입력값(x)를 받는 미지의목적 함수(f(x))를 상정하여,
해당함숫값(f(x))을최대로 만드는최적해를 찾는 것을 목적으로 합니다.
즉, 목적 함수(탐색대상함수)와 하이퍼파라미터 쌍(pair)을 대상으로 Surrogate Model(대체 모델) 을 만들고,
순차적으로 하이퍼 파라미터를 업데이트해 가면서평가를 통해 최적의 하이퍼파라미터 조합을 탐색합니다.
이 때의목점 함수를black-box function이라고 합니다.
Bayesian Optimization에는두 가지 필수 요소가 존재합니다.
먼저Surrogate Model은, 현재까지 조사된 입력값-함숫결과값 점들 (x1, f(x1)),...,(xt, f(xt)) 을 바탕으로, 미지의 목적 함수의 형태에 대한확률적인 추정을 수행하는 모델을 지칭합니다.
그리고Acquisition Function은, 목적 함수에 대한 현재까지의 확률적 추정 결과를 바탕으로,‘최적 입력값을 찾는 데 있어 가장 유용할 만한’다음 입력값 후보를 추천해 주는 함수를 지칭합니다.
Bayesian Optimization 수행 과정
자세한 수행 과정
입력값, 목적 함수 및 그 외 설정값들을 정의한다.
입력값 x : 여러가지 hyperparameter
목적 함수 f(x) : 설정한 입력값을 적용해 학습한, 딥러닝 모델의 성능 결과 수치(e.g. 정확도)
입력값 x 의 탐색 대상 구간 : (a,b)
입력값-함숫결과값 점들의 갯수 : n
조사할 입력값-함숫결과값 점들의 갯수 : N
설정한 탐색 대상 구간 (a,b) 내에서 처음 n 개의 입력값들을 랜덤하게 샘플링하여 선택한다.
선택한 n 개의 입력값 x1, x2, ..., xn 을 각각 모델의 하이퍼 파라미터로 설정하여 딥러닝 모델을 학습한 뒤, 학습이 완료된 모델의 성능 결과 수치를 계산한다.
이들을 각각 함숫결과값 f(x1), f(x2), ..., f(xn) 으로 간주한다.
입력값-함숫결과값 점들의 모음 (x1, f(x1)), (x2, f(x2)), ..., (xn, f(xn)) 에 대하여 Surrogate Model(대체 모델) 로 확률적 추정을 수행합니다.
조사된 입력값-함숫결과값 점들이 총 N 개에 도달할 때까지, 아래의 과정을 반복적으로 수행한다.
기존 입력값-함숫결과값 점들의 모음 (x1, f(x1)),(x2, f(x2)), ..., (xt, f(xt)) 에 대한 Surrogate Model (대체 모델)의 확률적 추정 결과를 바탕으로, 입력값 구간 (a,b) 내에서의 EI 의 값을 계산하고, 그 값이 가장 큰 점을 다음 입력값 후보 x1 로 선정한다.
다음 입력값 후보 x1 를 hyperparameter 로 설정하여 딥러닝 모델을 학습한 뒤, 학습이 완료된 모델의 성능 결과 수치를 계산하고, 이를 f(x1) 값으로 간주한다.
새로운 점 (x2, f(x2)) 을 기존 입력값-함숫결과값 점들의 모음에 추가하고, 갱신된 점들의 모음에 대하여 Surrogate Model 로 확률적 추정을 다시 수행한다.
총 N 개의 입력값-함숫결과값 점들에 대하여 확률적으로 추정된 목적 함수 결과물을 바탕으로, 평균 함수 μ(x) 을 최대로 만드는 최적해를 최종 선택합니다. 추후 해당값을 하이퍼파라미터로 사용하여 딥러닝 모델을 학습하면, 일반화 성능이 극대화된 모델을 얻을 수 있다.
RNN이란 Recurrence Neural Network라는 인공 신경망으로써, 자연어처리에 용이한 딥러닝 기법 중 하나이다.
recursive한 말 그대로 과거의 데이터를 누적하여 학습에 사용함으로써, 언어처리, 문장,맥락 등을 이해하기 위해서다.
RNN은 따라서 음성인식, 언어 모델링, 번역 등 다양한 분야에서 쓰이고 있다.
이 RNN의 핵심이 바로 LSTM이다.
LSTM은 RNN의 특별한 한 종류로, 특정 상황에서는 RNN보다 훨씬 효율적으로 해결할 수 있다.
RNN / LSTM 의 특징은 아래의 예시를 들어 설명할 수 있다.
1) 구름은 xx에 있다. 에서 xx를 예측하는것은 쉽다.
하지만
2) 나는 프랑스에서 자랐다. 따라서 나는 자연스럽게 축구를 좋아한다. 그리고 나는 xx어를 유창하게 할 수 있다.
위 2번의 답을 예측하려면 정답에 필요한 정보를 얻기 위해 훨씬 앞 혹은 뒤에서 정보를 찾아야 한다.
따라서 정보를 얻기 위한 시간격차가 커지게 된다.
RNN은 안타깝게도 격차가 늘어날 수록 효율성이 매우 떨어진다고 한다.
GPT에 물어보니 기울기 소실, 기울기 문제 폭발 두 가지 때문이라고 한다.
LSTM은 RNN의 긴 시간격차로 발생하는 문제를 보완하기 위해 생겨난 아키텍쳐라고 한다.
이제 본격적으로 LSTM을 알아보자.
앞서 말했듯이, LSTM은 RNN에 비해 장기적인 문제를 해결하는데 탁월하다고 했다.
먼저 RNN의 구조와 LSTM의 구조를 그림을 통해 살펴보자.
< RNN >
< LSTM >
LSTM의 핵심
LSTM의 핵심 아이디어는 cell state이다. 아래에서 수평으로 그어진 윗 선을 말한다.cell state= 흐르는 물이라고 생각
LSTM은 cell state에 뭔가를 더하거나 없앨 수 있는 능력이 있는데,
이 능력은 gate라고 불리는 구조에 의해서 조심스럽게 제어된다.
Gate는 정보가 전달될 수 있는 추가적인 방법으로, sigmoid layer와 pointwise 곱셈으로 이루어져 있다.
LSTM의 첫 단계로는 cell state로부터 어떤 정보를 버릴 것인지를 정하는 것으로, sigmoid layer에 의해 결정된다.
그래서 이 단계의 gate를 "forget gate layer"라고 부른다. ( = 망각층 )
이 단계에서는 \(h_{t-1}\)과 \(x_t\)를 받아서 0과 1 사이의 값을 \(C_{t-1}\)에 보내준다. 그 값이 1이면 "모든 정보를 보존해라"가 되고, 0이면 "죄다 갖다버려라"가 된다.
아까 얘기했던 이전 단어들을 바탕으로 다음 단어를 예측하는 언어 모델 문제로 돌아가보겠다. 여기서 cell state는 현재 주어의 성별 정보를 가지고 있을 수도 있어서 그 성별에 맞는 대명사가 사용되도록 준비하고 있을 수도 있을 것이다. 그런데 새로운 주어가 왔을 때, 우리는 기존 주어의 성별 정보를 생각하고 싶지 않을 것이다.
< 망각층 >
다음 단계는 앞으로 들어오는 새로운 정보 중 어떤 것을 cell state에 저장할 것인지를 정한다.
먼저, "input gate layer"라고 불리는 sigmoid layer가 어떤 값을 업데이트할 지 정한다.
그 다음에 tanh layer가 새로운 후보 값들인 \(\tilde{C}_t\) 라는 vector를 만들고, cell state에 더할 준비를 한다.
이렇게 두 단계에서 나온 정보를 합쳐서 state를 업데이트할 재료를 만들게 된다.
다시 언어 모델의 예제에서, 기존 주어의 성별을 잊어버리기로 했고, 그 대신 새로운 주어의 성별 정보를 cell state에 더하고 싶을 것이다.
새 정보 유입 -> < input gate >
이제 과거 state인 \(C_{t-1}\)를 업데이트해서 새로운 cell state인 \(C_t\)를 만들 것이다. 이미 이전 단계에서 어떤 값을 얼마나 업데이트해야 할 지 다 정해놨으므로 여기서는 그 일을 실천만 하면 된다.
LSTM의 핵심
cell state가 존재하고 RNN과 달리 한 cell마다 네 개의 layer가 존재.
망각층과 입력층을 통해 cell을 계속 업데이트해가며 학습을 진행하는 메카니즘이다.
RNN과 비슷하다는 느낌이기 때문에 당연히 자연어처리에 특화되어 있고,
장기 데이터 처리, 학습, 예측에도 용이하기 때문에 시계열 데이터에도 유용하게 쓰인다고 한다.
학습률을 서서히 낮추는 가장 간단한 방법은 "전체"의 학습률을 값을 일괄적으로 낮추는 것이다.
이를 더욱 발전시킨 것이 AdaGrad이다.
Adagrad는 전체에서 발전해 "각각"의 매개변수에 맞게 갱신해준다.
'적응적 학슙를'을 기반으로 한 옵티마이저이다.
Adagrad, RMSprop = 적응적 학습률 기반
momentum이라는 개념을 이용하여 gradient를 조절
어떻게 개별 매개변수마다 갱신을 해줄까? 자세히 알아보자.
위 수식에서 h는 기존 기울기값을 제곱하여 계속 더해준다.
그리고 매개변수를 갱신할 때 1/ √h를 곱해서 학습률을 조정한다.!!
이 뜻은 매개변수 원소 중에서 많이 움직이는 원소는 학습률이 낮아진다는 뜻이라고 볼 수 있다.
(다시 말해 학습률 감소가 매개변수 원소마다 다르게 작용됨.)
손코딩
classAdaGrad:def__init__(self, lr=0.01):
self.lr = lr
self.h = Nonedefupdate(self, params, grads):if self.h inNone:
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
parmas[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
주의) 마지막 줄에서 1e-7를 더해주는 부분. 1e-7은 self.h[key]에 0이 담겨 있어도 0으로 나누는 것을 막아줌.
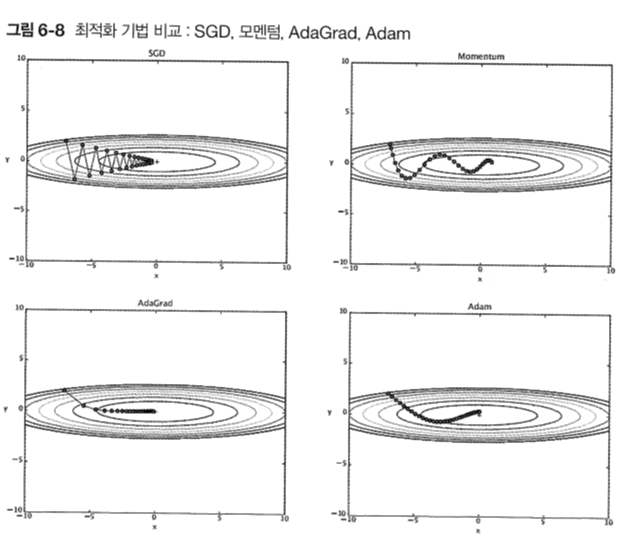
Adagrad의 갱신경로를 그림으로 보자.
최소값을 향해 효율적인 움직임을 보여준다.!!
6.1.6 아담 ( Adam )
모멘텀은 공을 구르는 듯한 움직임을 보여준다. Adagrad는 원소 개별적으로 갱신해주었다.
이 둘을 합치면 Adam이라고 할 수 있다.
그림을 먼저 보자.
모멘텀과 비슷한 패턴이지만, 좌우 흔들림이 적은 것을 볼 수 있다.
이는 학습의 갱신 강도를 적응적으로 조정해서 얻는 benefit이라고 한다.
마지막으로 정리해서 봐보자.
무엇이 제일 좋다!! 라는 것은 데이터, 목적, 그 밖의 하이퍼 파라미터에 따라 다르기 때문에 정해진 것이 없다.
하지만 통상적으로 SGD보다 momentum,adam,adagrad 3개가 더 좋고, 일반적으로 Adam을 많이 쓴다고 한다.
6.2 가중치의 초기값
신경망 학습에서 가중치 초기값이 매우 중요하다고 한다.
2절에서는 권장 초기값을 배우고 실제로 학습이 잘 이루어지는지 확인해보자.
6.2.1 초기값을 0으로 하면?
이제부터 오버피팅을 억제해 범용 성능을 높이는 테크닉인 가중치 감소 기법을 소개해주겠다.
가중치 감소는 가중치 매개변수의 값이 작아지도록 학습하는 방법이다.
가중치 값을 작게 해서 오버피팅을 일어나지 않도록 하게 하는 것이다.
가중치 값을 작게 만들고 싶으면 초기값도 최대한 작은 값에서 시작하는 것이 정공법이기 때문에,,!
사실 지금까지 가중치 초기값은 0.01 * np.random.randn(10,100)처럼 정규분포에 생성된 값에 0.01배를 한 작은값을 사용
했었다.
그렇다면 가중치 초기값을 모두 0으로 설정하면 어떨까??
결론부터 말하자면, 아주 안좋은 생각이다.
실제로 가중치 초기값을 0으로 하면 학습이 올바로 이루어지지 않는다.
오차역전파법에서 모든 가중치의 값이 똑같이 갱신되기 때문이다.
예를 들어 2층 신경망에서 첫 번째, 두 번째 층의 가중치가 0이라고 가정해보자.
그럼 순전파 때는 입력층의 가중치가 0이기 때문에 두 번째 층의 뉴런에 모두 같은 값이 전달된다.
두 번째 층의 모든 뉴런에 같은 값이 입력된다는 것은 역전파 두 번 층의 가중치가 모두 똑같이 갱신된다는 말과 같다.
(곱셈 노드의 역전파를 기억해보자.)
그래서 가중치들을 같은 초기값에서 시작하고 갱신을 거쳐도 여전히 같은 값을 유지하는 것이다.
이는 가중치를 여러 개 갖는 의미를 사라지게 한다.
이 '가중치가 고르게 되어버리는 상황'을 막으려면 초기값을 무작위로 설정해야 한다.
6.2.2 은닉층의 활성화값 분포
은닉층의 활성화값(활성화 함수의 출력 데이터)의 분포를 관찰하면 중요한 정보를 얻을 수 있었다.
이번 절에서는 가중치의 초기값에 따라 은닉층 활성화 값들이 어떤 분포를 갖는지 시각화 해보려한다.
예시로 5층의 신경망을 가정, 시그모이드 함수 사용, 입력데이터 무작위로 선정
import numpy as np
import matplotlib.pyplot as plt
defsigmoid(x):return1 / (1 + np.exp(-1))
x = np.random.randn(1000, 100) # 1000개의 데이터
node_num = 100# 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5# 은닉층이 5개
activations = {} # 이 곳에 활성화 결과(활성화값)를 저장
fro i inrange(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z
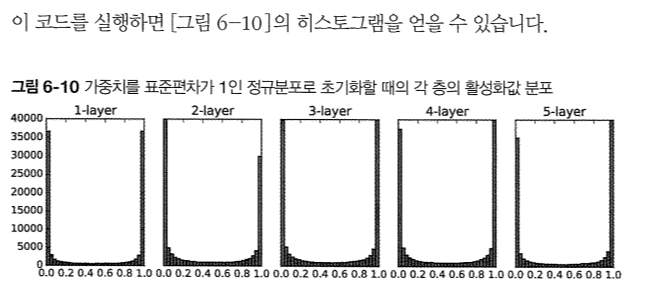
층은 5개, 각 층의 뉴런은 100개씩이다.
활성화 값들의 분포를 그려보자.
# 히스토그램 그리기for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + '-layer')
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()
각 층의 활성화 값들이 0과 1에 치우쳐져 있다.
시그모이드 함수는 출력이 0또는 1에 가까워지면 미분값은 0에 수렴한다.
따라서 데이터가 0과 1에 치우쳐 분포하게 되면 역전파 기울기 값이 점점 작아지다가 사라진다.
이를 기울기 소실 현상 ( gradient vanishing )이라고 한다.
이제 표준편차를 0.01로 바꿔서 다시 그려보면 다음과 같은 그래프를 얻을 수 있다.
아까와 같은 기울기 소실 문제는 보이지 않지만, 모두 중간값에 몰빵되있는 것을 볼 수 있다.
이는 표현력 관점에서 문제라고 볼 수 있다.
Xavier 초기값
사비에르 초기값이란 사비에르가 작성한 논문에서 발췌한 것으로, 현재까지 딥러닝 프레임워크에서 많이 사용한다.
.신경망의 순전파에서는 가중치 총합의 신호를 계산하기 위해 행렬 곱을 사용했다 ( np.dot )
그리고 행렬 곱의 핵심은 원소 개수 (차원 개수)를 일치시키는 것이다.
예시를 통해 그림으로 이해해보자. (계산 그래프)
X,W,B가 있다고 하자. 각각 입력, 가중치, 편향이고 shape은 각각(2,) , (2,3), (3,)이다.
X와 W가 들어와 np.dot을 통해 행렬 곱 수행 -> x * W -> ( x * W ) +B = Y
이제 역전파를 알아보자.
아래 식이 도출되는것을 확인하자.
WT는 T의 전치행렬을 말함.
(전치행렬 = Wij 를 Wji로 바꾼것. 아래 그림 참조)
위 식을 통해서 계산 그래프의 역전파를 구해보자.
위 그림의 네모 박스 1,2를 유심히 살펴보자. (덧셈노드는 그대로 흐르고, 곱셈 노드는 교차하므로 !!)
X,W,B의 shape은 각각(2,) , (2,3), (3,)이다.
∂L/∂Y는 (3,) 인데 W인 (2,3)과 차원이 달라 곱셈이 되지 않는다.
따라서 WT를 통해 (3,2)로 바꿔 곱셈을 수행할 수 있도록 변환 (+X도 마찬가지)
5.6.2 배치용 Affine 계층
지금까지 예시로 든것은 X (입력 데이터)가 하나일 때만 고려한 상황이였다.
하지만 현실에서는 하나일 확률이 매우 적으므로 실제 Affine 계층을 생각해보자.
입력 데이터가 N개일 경우이다.
5.6.3 Softmax-with-Loss 계층
마지막으로 배울 것은 출력층에서 사용하는 소프트맥스 함수이다.
딥러닝에서는 학습과 추론 두 가지가 있다.
일반적으로 추론일 때는 Softmax 계층(layer)을 사용하지 않는다. Softmax 계층 앞의 Affine 계층의 출력을 점수(score)라고 하는데, 딥러닝의 추론에서는 답을 하나만 예측하는 경우에는 가장 높은 점수만 알면 되므로 Softmax 계층이 필요없다. 반면, 딥러닝을 학습할 때는 Softmax 계층이 필요하다.
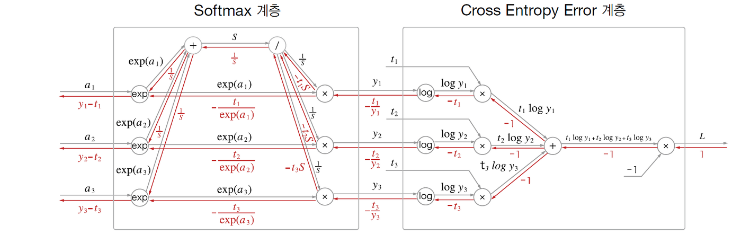
이제 소프트맥스 계층을 구현할텐데, 손실 함수인 엔트로피 오차도 포함하여 계산 그래프를 살펴보자.
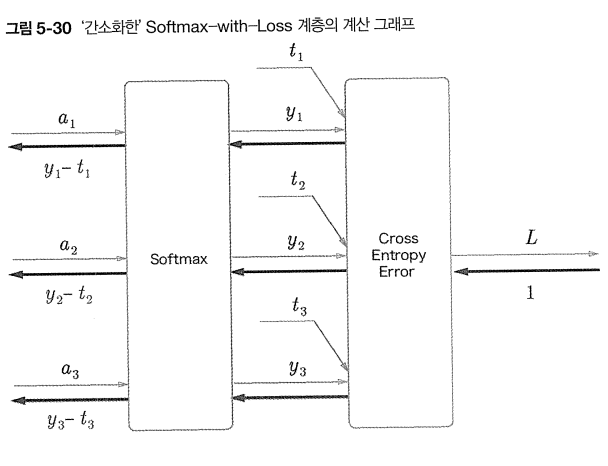
너무 복잡하다. 간소화 해보자.
여기서는 3클래스 분류를 가정하고 이전 계층에서 3개의 입력(점수)를 받는다.
그림과 같이 Softmax 계층은 입력 a1,a2,a3를 정규화하여 y1,y2,y3를 출력함