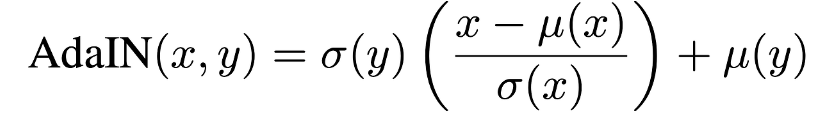이는 곧 output에서 이전 레이어에서 학습한 정보를 연결함으로써 현재 층에서는 추가적으로 학습해야 할 정보만을 Mapping(학습)하면 된다는 것을 의미한다.
그리고 학습이 계속 진행되면서, 층의 깊이가 깊어질수록 (학습이 많이 될 수록) x는 출력값 y에 근접하게 되어 f(x)는 최종적으로 0에 수렴하게 될 것이다.
수식을 보면서 이해하자면, y = f(x) + x 에서 추가 학습량에 해당하는 F(x) = H(x) - x가 최소값(0)이 되도록 학습이 진행된다.
Architecture
Renset은 기본적으로 VCG-19의 구조를 뼈대로 하고 있다고 한다.
VCG-19층에 ConV층들을 추가해서 깊게 만든 이후에, shortcut(Residual Block)을 추가하는 것이 전부라고 한다.
아래 그림은 34층의 ResNet과 거기에서 shortcut들을 제외한 버전인 plain 네트워크의 구조이다.
그림 -> 34층의 Resnet은 처음을 제외하고 균일하게 3x3 사이즈의 ConV 필터를 사용함을 알 수 있다.
그리고 특성맵의 사이즈가 반으로 줄어들 때, 특성맵의 Depth를 2배로 높였다.
아래 그림은 18층&34층의 기존 network와 Resnet을 비교한 것이다.
y축(오차)를 동일하게 보았을 때, Resnet의 오차율이 더 적은것을 볼 수 있다.
왼쪽 그래프를 보면 plain 네트워크는 망이 깊어지면서 오히려 에러가 커졌음을 알 수 있다. 34층의 plain 네트워크가 18층의 plain 네트워크보다 성능이 나쁘다. 반면, 오른쪽 그래프의 ResNet은 망이 깊어지면서 에러도 역시 작아졌다! shortcut을 연결해서 잔차(residual)를 최소가 되게 학습한 효과가 있다는 것이다. 아래 표는 18층, 34층, 50층, 101층, 152층의 ResNet이 어떻게 구성되어 있는가를 잘 나타내준다.
18-Layer의 경우는 conv2_x에서 2X2, conv3_x에서 2X2, conv4_x에서 2X2, conv5_x에서 2X2, 입력1, 출력1해서 1+2×2+2×2+2×2+2×2+1=18이 된다.
다음 표는 ResNet에서 Layer가 깊을 수록 더 좋은 성능을 보여준다는 것을 나타낸다.
CIFAR-10, CIFAR-100은 머신러닝 용 이미지 분류 데이터셋을 말하며 CIFAR-10 dataset이 10개의 클래스로 분류가 되고 CIFAR-100 dataset이 100개의 클래스로 분류가 된다. 위의 표를 보면 CIFAR-10, CIFAR-100둘다 ResNet의 layer가 깊을 수록 error율(%)이 더 작은 것을 볼 수 있다.
심화
Resnet은 2개 이상의 Conv Layer와 skip-connection을 활용해서 Residual Block을 만들어서 네트워크를 구성한다.
앞서 말했듯, Neural Network 층을 깊게 쌓으면 기울기 소실이 발생하기 때문에 마냥 좋은 것이 아니다.
그렇다면 Residual Block이 기울기 소실을 어떻게 피할까?
먼저 용어부터 정리하고 가자.
l : 현재 layer의 index L : 전체 layer의 갯수 W : 가중치 행렬 F : Residual Function f : Activation Function(ReLU) h : Identity Mapping을 위한 Dimension 세팅용 함수
활성함수 f(yl)을 identity mapping이라고 가정하면, xl+1=f(yl)=yl=xl+F(xl,Wl) xl+1=xl+F(xl,Wl) (참고로 identify mapping은 입력으로 들어간 x가 어떠한 함수를 통과해도 다시 x가 나오는 것으로 항등함수 F(x)=x가 대표적인 identity mapping에 해당한다.) (h도 identity mapping으로 가정했으므로 x가 그대로 사용된다.) 이 식으로부터 일반화식을 표현하면 다음과 같이 나타낼 수 있다. xL=xl+i=l∑L−1F(xi,Wi) Loss function의 gradient의 계산식은 backward propagation chain rule로 부터 아래 식으로 나타낼 수 있다.
위 식에서 우리는 ∂xl ∂ε가 두 개 값의 합으로 분해할 수 있다는것을 알 수 있다.
먼저,(1) 앞 부분의 ∂xL * ∂ε은 weight layer와 무관하게 다이렉트로 전파되는 정보이다. 따라서 정보는 어떤 layer든 같은 정보가 전파된다. (2) 뒷 부분의 ∂xL∂ε∂xl∂i=1∑L−1F(xi,Wi) 은 weight layer를 거쳐 전파되는 정보이다. backward propagation을 할 때 ∂xl∂ε 이 0이 되기 위해서는 weight layer를 거쳐 역전파되는 값이 -1이 되어야 한다. 실제 학습을 할 때 전체 데이터를 한번에 학습하는것이 아닌 데이터의 일부분씩 학습하는 mini-batch방식이 사용되는데, 모든 mini-batch에서 역전파값이 -1이 되는것은 불가능에 가깝다. 때문에 ∂xl∂ε 은 항상 0이 아닌 어떠한 값을 갖게 되고, 역전파된 값이 0에 가깝게 되는 vanishing gradient가 발생하지 않게 된다.
Resnet논문에 BottleNeck / 배치 정규화 적용 여부에 따른 성능 비교 부분은 패스~~
GAN은 비지도학습이기 때문에 Accuracy 나 Confusion Matrix 등의 개념을 사용할 수 가 없다.
여기 Style GAN은 FID / PPL 라는 방법을 사용하여 성능을 평가한다고 한다.
FID (Frechat Inception Distance)
Frechat Inception Distance(FID)는 생성된 이미지의 분포가 원본 이미지의 분포에 얼마나 가까운지 측정한다.
그러나 이미지는 고차원 공간에 매장되어 있기(embedded) 때문에 분포의 거리를 쉽게 측정할 수 없다.
따라서 FID는 저차원 공간에 이미지를 매장(embedded)하고 그 공간에서 분포의 거리를 측정하는 것이다. (매니폴드의 개념과 유사)
FID 공식은 아래와 같다.
FID 공식
m과 c는 임베디드 공간의 평균 벡터(mean vectors)와 공변량 행렬(covariance matrices)이다.
아래 첨자로 w가 있는 기호는 생성된 이미지이고, 아래 첨자가 없는 것은 실제 이미지이다.
이것이 분포의 거리를 보여주기 때문에 값이 작을수록 가짜 이미지가 진짜 이미지처럼 보인다.
이것은 생성자가 더 나은 성능을 보여준다는 것을 가리킨다.
(GPT에게 FID 수식을 자세히 설명해달라고 했다.)
복잡하게 생각할 필요없이,
m과 c만 보면, 실제와 유사한 이미지를 만들었다고 하면 좌측 |m-m|은 0에 수렴, 우측 또한 0에 수렴할 것이다.
Perceptual Path Length (PPL)
Perceptual Path Length, PPL은 이미지가 지각적으로 부드럽게 바뀌었는지에 대한 지표이다.
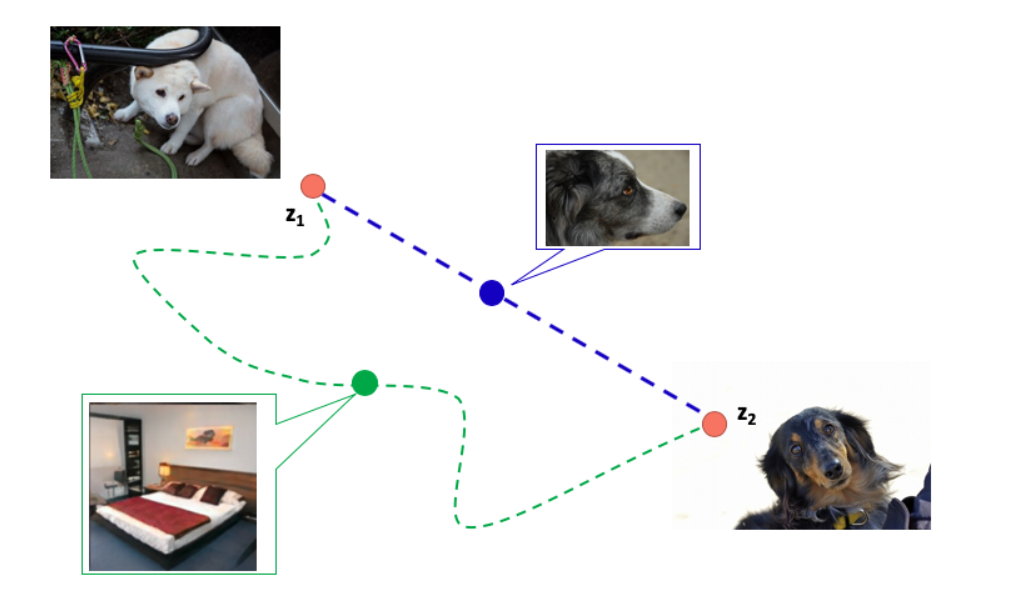
우리가 하얀 개를 생산하는 잠재 변수인 z1과 검정 개를 생산하는 잠재 변수 z2가 있다고 생각해 보자.
색깔 이외의 다른 요소는 바뀌지 않았으므로 중간의 데이터의 잠재 변수는 흰색과 검은색 사이의 경로에 따라 바뀌는 게 이상적이다.
즉 회색 개가 나오는 게 목표라고 할 수 있다. 다시 말해 색만 바뀌는 파란색 경로는 "지각적으로(perceptually)" 가장 짧은 거리이다.
반대로 객체의 모양을 바꾸고 침대와 같은 이미지를 통과하는 초록색 경로는 "지각적으로(perceptually)" 거리가 멀다.
이는 PPL로 정량화됐고 공식의 정의는 다음과 같다. 이것은 두 잠재 변수 z_1과 z_2를 비 t로 혼합해서(mixed) 얻어진 잠재 변수와 이 둘을 t + ε의 비율로 혼합해서(mixed) 얻은 잠재 변수에 의해 생성된 이미지 사이 거리의 기댓값이다.
FID와 마찬가지로 PPL값이 작을 수록 실제 이미지와 만들어진 이미지가 유사(부드럽게)한 것을 나타낸다.
Style GAN
이제 StyleGAN에서 주로 쓰이는 평가 지표인 FID와 PPL을 토대로, 본격적으로 Style GAN에 대해서 알아보자.
우선 Style GAN은 두 가지 특징이 있다고 한다.
1. 고 해상도의 이미지를 Progressive Growing을 통해 생성한다. (PG GAN의 느낌(?))
2. AdaIN을 통해 각 레이어에 이미지와 스타일을 결합한다.
첫 번째로 이 두 가지 특징과 StyleGAN의 세부적 구조에 대해서 들어가보자.
Progressive Growing
Progressive Growing은 Progressive-Growing(PG-GAN)에서 제안된 고해상도 이미지를 생성하는 방법이다. 대략 말하면 이는 저해상도의 이미지부터 시작해 점진적으로 고해상도 생성자(Generators)와 판별자(Discriminators)를 추가하여 고해상도 이미지를 만드는 방법이다. (계층적 구조를 가짐)
AdaIN
AdaIN은 2017년 Xun Huang 외에 의해 제안된 style transfer의 정규화(normalization) 방법이다. 수학식은 아래와 같다.
x: content input
y: style input
->평균과 분산으로 정규화한다.
AdaIN은 다른 정규화(normalization) 방법과는 달리 오직 스타일과 콘텐츠 이미지의 통계로만 수행된다.
그리고 학습되는 파라미터는 쓰이지 않는다.
이는 학습 데이터에서 한 번도 본 적 없는 스타일로 변환할 수 있도록 한다.
Network architecture of StyleGAN
StyleGAN의 키포인트는 다음과 같다.
점진적으로 해상도를 올리기 위해서 Progressive Growing을 사용한다.
일반적인 GANs에서처럼 확률적(stochastically)으로 생성된 잠재 변수를 통해 이미지를 생성하는 것이 아닌 고정된 값의 텐서(fixed value tensor)를 통해 이미지를 생성한다.
확률적(stochastically)으로 생성된 잠재 변수는 8-layer의 비선형 변환 신경망을 통과한 후 각 해상도에 AdaIN을 통해 스타일 벡터로 사용한다.
위 그림의 (a)는 PG-GAN이고 (b)는 StyleGAN이다. 둘 다 점진적으로 해상도를 올리는 progressive growing을 사용한다.
그러나 PG-GAN은 확률적 잠재 변수 z로부터 이미지를 생성하는 반면, StyleGAN은 고정된 4x4x512 텐서로부터 이미지를 생성한다.
게다가 확률적 잠재 변수는 그대로 쓰이지 않고 스타일로서 쓰이기 전, Mapping Network라 불리는 fully connected
network로 비선형 변환을 해 준다.
Mixing Regularization
StyleGAN은 Mixing Regularization이라 불리는 정규화(regularization) 방법을 사용하는 데, 이는 스타일에 사용된 두 잠재 변수를 학습하는 동안 혼합(mixes)하는 것이다. 예를 들어 스타일 벡터인 w_1과 w_2가 잠재 변수인 z_1과 z_2에서부터 맵핑(mapped)되었다고 할 , w_1은 4x4의 이미지를 생성할 때 사용되고 w_2는 8x8의 이미지를 생성할 때 사용된다.
RNN이란 Recurrence Neural Network라는 인공 신경망으로써, 자연어처리에 용이한 딥러닝 기법 중 하나이다.
recursive한 말 그대로 과거의 데이터를 누적하여 학습에 사용함으로써, 언어처리, 문장,맥락 등을 이해하기 위해서다.
RNN은 따라서 음성인식, 언어 모델링, 번역 등 다양한 분야에서 쓰이고 있다.
이 RNN의 핵심이 바로 LSTM이다.
LSTM은 RNN의 특별한 한 종류로, 특정 상황에서는 RNN보다 훨씬 효율적으로 해결할 수 있다.
RNN / LSTM 의 특징은 아래의 예시를 들어 설명할 수 있다.
1) 구름은 xx에 있다. 에서 xx를 예측하는것은 쉽다.
하지만
2) 나는 프랑스에서 자랐다. 따라서 나는 자연스럽게 축구를 좋아한다. 그리고 나는 xx어를 유창하게 할 수 있다.
위 2번의 답을 예측하려면 정답에 필요한 정보를 얻기 위해 훨씬 앞 혹은 뒤에서 정보를 찾아야 한다.
따라서 정보를 얻기 위한 시간격차가 커지게 된다.
RNN은 안타깝게도 격차가 늘어날 수록 효율성이 매우 떨어진다고 한다.
GPT에 물어보니 기울기 소실, 기울기 문제 폭발 두 가지 때문이라고 한다.
LSTM은 RNN의 긴 시간격차로 발생하는 문제를 보완하기 위해 생겨난 아키텍쳐라고 한다.
이제 본격적으로 LSTM을 알아보자.
앞서 말했듯이, LSTM은 RNN에 비해 장기적인 문제를 해결하는데 탁월하다고 했다.
먼저 RNN의 구조와 LSTM의 구조를 그림을 통해 살펴보자.
< RNN >
< LSTM >
LSTM의 핵심
LSTM의 핵심 아이디어는 cell state이다. 아래에서 수평으로 그어진 윗 선을 말한다.cell state= 흐르는 물이라고 생각
LSTM은 cell state에 뭔가를 더하거나 없앨 수 있는 능력이 있는데,
이 능력은 gate라고 불리는 구조에 의해서 조심스럽게 제어된다.
Gate는 정보가 전달될 수 있는 추가적인 방법으로, sigmoid layer와 pointwise 곱셈으로 이루어져 있다.
LSTM의 첫 단계로는 cell state로부터 어떤 정보를 버릴 것인지를 정하는 것으로, sigmoid layer에 의해 결정된다.
그래서 이 단계의 gate를 "forget gate layer"라고 부른다. ( = 망각층 )
이 단계에서는 \(h_{t-1}\)과 \(x_t\)를 받아서 0과 1 사이의 값을 \(C_{t-1}\)에 보내준다. 그 값이 1이면 "모든 정보를 보존해라"가 되고, 0이면 "죄다 갖다버려라"가 된다.
아까 얘기했던 이전 단어들을 바탕으로 다음 단어를 예측하는 언어 모델 문제로 돌아가보겠다. 여기서 cell state는 현재 주어의 성별 정보를 가지고 있을 수도 있어서 그 성별에 맞는 대명사가 사용되도록 준비하고 있을 수도 있을 것이다. 그런데 새로운 주어가 왔을 때, 우리는 기존 주어의 성별 정보를 생각하고 싶지 않을 것이다.
< 망각층 >
다음 단계는 앞으로 들어오는 새로운 정보 중 어떤 것을 cell state에 저장할 것인지를 정한다.
먼저, "input gate layer"라고 불리는 sigmoid layer가 어떤 값을 업데이트할 지 정한다.
그 다음에 tanh layer가 새로운 후보 값들인 \(\tilde{C}_t\) 라는 vector를 만들고, cell state에 더할 준비를 한다.
이렇게 두 단계에서 나온 정보를 합쳐서 state를 업데이트할 재료를 만들게 된다.
다시 언어 모델의 예제에서, 기존 주어의 성별을 잊어버리기로 했고, 그 대신 새로운 주어의 성별 정보를 cell state에 더하고 싶을 것이다.
새 정보 유입 -> < input gate >
이제 과거 state인 \(C_{t-1}\)를 업데이트해서 새로운 cell state인 \(C_t\)를 만들 것이다. 이미 이전 단계에서 어떤 값을 얼마나 업데이트해야 할 지 다 정해놨으므로 여기서는 그 일을 실천만 하면 된다.
LSTM의 핵심
cell state가 존재하고 RNN과 달리 한 cell마다 네 개의 layer가 존재.
망각층과 입력층을 통해 cell을 계속 업데이트해가며 학습을 진행하는 메카니즘이다.
RNN과 비슷하다는 느낌이기 때문에 당연히 자연어처리에 특화되어 있고,
장기 데이터 처리, 학습, 예측에도 용이하기 때문에 시계열 데이터에도 유용하게 쓰인다고 한다.