https://prowiseman.tistory.com/entry/StyleGAN-StyleGAN2
StyleGAN / StyleGAN2
들어가며 StyleGAN과 StyleGAN2의 논문을 살짝 읽어보긴 했는데, 수식이 너무 어려워서 곤란해하던 중 From GAN basic to StyleGAN2 이란 포스트에 잘 정리돼 있어 위 포스트를 보고 공부하였다. 그래서 아래
prowiseman.tistory.com
본 포스트는 위 글을 100% 참조하여 쓴 글이다.
바로 본론으로 들어가보자.
GAN의 평가 지표
GAN은 비지도학습이기 때문에 Accuracy 나 Confusion Matrix 등의 개념을 사용할 수 가 없다.
여기 Style GAN은 FID / PPL 라는 방법을 사용하여 성능을 평가한다고 한다.
FID (Frechat Inception Distance)
Frechat Inception Distance(FID)는 생성된 이미지의 분포가 원본 이미지의 분포에 얼마나 가까운지 측정한다.
그러나 이미지는 고차원 공간에 매장되어 있기(embedded) 때문에 분포의 거리를 쉽게 측정할 수 없다.
따라서 FID는 저차원 공간에 이미지를 매장(embedded)하고 그 공간에서 분포의 거리를 측정하는 것이다. (매니폴드의 개념과 유사)
FID 공식은 아래와 같다.

m과 c는 임베디드 공간의 평균 벡터(mean vectors)와 공변량 행렬(covariance matrices)이다.
아래 첨자로 w가 있는 기호는 생성된 이미지이고, 아래 첨자가 없는 것은 실제 이미지이다.
이것이 분포의 거리를 보여주기 때문에 값이 작을수록 가짜 이미지가 진짜 이미지처럼 보인다.
이것은 생성자가 더 나은 성능을 보여준다는 것을 가리킨다.
(GPT에게 FID 수식을 자세히 설명해달라고 했다.)

복잡하게 생각할 필요없이,
m과 c만 보면, 실제와 유사한 이미지를 만들었다고 하면 좌측 |m-m|은 0에 수렴, 우측 또한 0에 수렴할 것이다.
Perceptual Path Length (PPL)
Perceptual Path Length, PPL은 이미지가 지각적으로 부드럽게 바뀌었는지에 대한 지표이다.
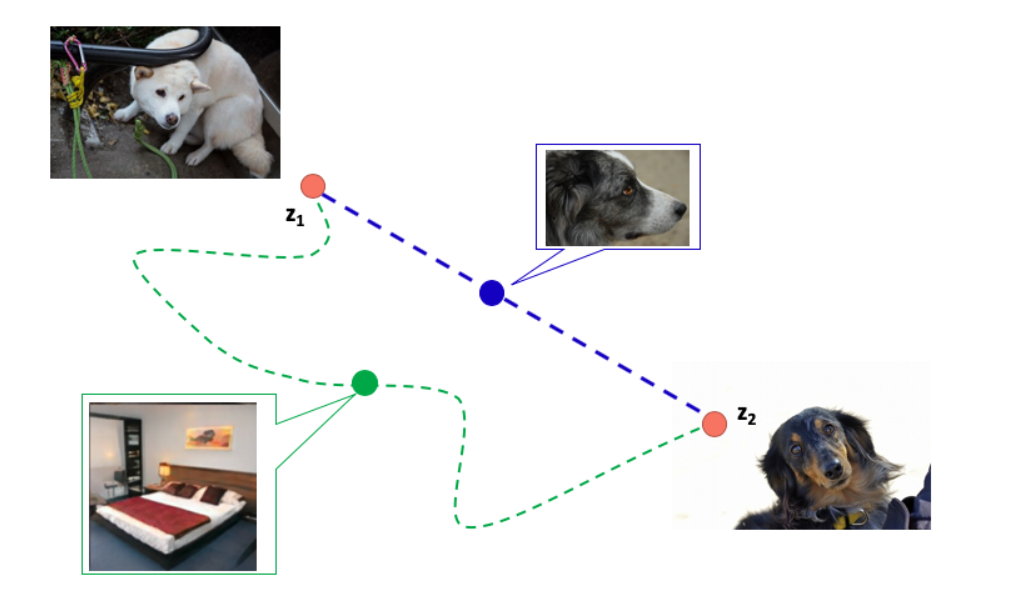
우리가 하얀 개를 생산하는 잠재 변수인 z1과 검정 개를 생산하는 잠재 변수 z2가 있다고 생각해 보자.
색깔 이외의 다른 요소는 바뀌지 않았으므로 중간의 데이터의 잠재 변수는 흰색과 검은색 사이의 경로에 따라 바뀌는 게 이상적이다.
즉 회색 개가 나오는 게 목표라고 할 수 있다. 다시 말해 색만 바뀌는 파란색 경로는 "지각적으로(perceptually)" 가장 짧은 거리이다.
반대로 객체의 모양을 바꾸고 침대와 같은 이미지를 통과하는 초록색 경로는 "지각적으로(perceptually)" 거리가 멀다.
이는 PPL로 정량화됐고 공식의 정의는 다음과 같다. 이것은 두 잠재 변수 z_1과 z_2를 비 t로 혼합해서(mixed) 얻어진 잠재 변수와 이 둘을 t + ε의 비율로 혼합해서(mixed) 얻은 잠재 변수에 의해 생성된 이미지 사이 거리의 기댓값이다.

FID와 마찬가지로 PPL값이 작을 수록 실제 이미지와 만들어진 이미지가 유사(부드럽게)한 것을 나타낸다.
Style GAN
이제 StyleGAN에서 주로 쓰이는 평가 지표인 FID와 PPL을 토대로, 본격적으로 Style GAN에 대해서 알아보자.
우선 Style GAN은 두 가지 특징이 있다고 한다.
1. 고 해상도의 이미지를 Progressive Growing을 통해 생성한다. (PG GAN의 느낌(?))
2. AdaIN을 통해 각 레이어에 이미지와 스타일을 결합한다.
첫 번째로 이 두 가지 특징과 StyleGAN의 세부적 구조에 대해서 들어가보자.
Progressive Growing
Progressive Growing은 Progressive-Growing(PG-GAN)에서 제안된 고해상도 이미지를 생성하는 방법이다. 대략 말하면 이는 저해상도의 이미지부터 시작해 점진적으로 고해상도 생성자(Generators)와 판별자(Discriminators)를 추가하여 고해상도 이미지를 만드는 방법이다. (계층적 구조를 가짐)
AdaIN
AdaIN은 2017년 Xun Huang 외에 의해 제안된 style transfer의 정규화(normalization) 방법이다. 수학식은 아래와 같다.
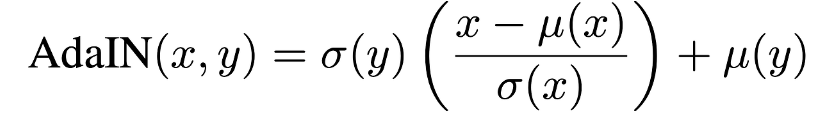
x: content input
y: style input
->평균과 분산으로 정규화한다.

AdaIN은 다른 정규화(normalization) 방법과는 달리 오직 스타일과 콘텐츠 이미지의 통계로만 수행된다.
그리고 학습되는 파라미터는 쓰이지 않는다.
이는 학습 데이터에서 한 번도 본 적 없는 스타일로 변환할 수 있도록 한다.
Network architecture of StyleGAN
StyleGAN의 키포인트는 다음과 같다.
- 점진적으로 해상도를 올리기 위해서 Progressive Growing을 사용한다.
- 일반적인 GANs에서처럼 확률적(stochastically)으로 생성된 잠재 변수를 통해 이미지를 생성하는 것이 아닌 고정된 값의 텐서(fixed value tensor)를 통해 이미지를 생성한다.
- 확률적(stochastically)으로 생성된 잠재 변수는 8-layer의 비선형 변환 신경망을 통과한 후 각 해상도에 AdaIN을 통해 스타일 벡터로 사용한다.

위 그림의 (a)는 PG-GAN이고 (b)는 StyleGAN이다. 둘 다 점진적으로 해상도를 올리는 progressive growing을 사용한다.
그러나 PG-GAN은 확률적 잠재 변수 z로부터 이미지를 생성하는 반면, StyleGAN은 고정된 4x4x512 텐서로부터 이미지를 생성한다.
게다가 확률적 잠재 변수는 그대로 쓰이지 않고 스타일로서 쓰이기 전, Mapping Network라 불리는 fully connected
network로 비선형 변환을 해 준다.
Mixing Regularization
StyleGAN은 Mixing Regularization이라 불리는 정규화(regularization) 방법을 사용하는 데, 이는 스타일에 사용된 두 잠재 변수를 학습하는 동안 혼합(mixes)하는 것이다. 예를 들어 스타일 벡터인 w_1과 w_2가 잠재 변수인 z_1과 z_2에서부터 맵핑(mapped)되었다고 할 , w_1은 4x4의 이미지를 생성할 때 사용되고 w_2는 8x8의 이미지를 생성할 때 사용된다.
이를 함으로써 아래 보이는 것과 같이 두 이미지의 스타일을 섞을 수 있다.
'부록' 카테고리의 다른 글
| 오차 역전파 & chain rule (0) | 2024.04.23 |
|---|---|
| Resnet 논문 리뷰 (0) | 2024.04.22 |
| LSTM (0) | 2023.08.02 |
| [Modeling] XGB Classifier + 그리드서치 / 베이지안 옵티마이저 (0) | 2023.03.18 |
| [딥러닝] 옵티마이저 [퍼온 글] (0) | 2023.03.06 |