
그래프 종류
1 : 선 그래프 (line plot)
시계열 데이터와 같이 연속적인 값의 변화와 패턴을 파악하는데 적합하다.

그래프 꾸미기 옵션
'o' = : 선 아닌 점그래프로 표현
marker = 'o' : 마커 모양 ('o' , '+', '*' 등등)
markerfacecolor='green' : 마커 배경색
markersize=10 : 마커 크기
color='olive' : 선의 색
linewidth = 2 : 선의 두께
label= : 라벨 지정
그래프 여러개 그리기
fig = plt.figure( figsize= ( x, y))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
sns.stripplot(~, ~, data=df, ax1)
2 : 면적 그래프
선 그래프와 같지만 그래프 아래 색이 입혀진다.
색의 투명도 alpha= num 으로 투명도 설정 가능
stacked = True / False 로 누적할지 여부 설정 가능 (default= True)

3 : 막대 그래프
막대 그래프 : 각 변수 사이 값의 크기 차이를 설명하는데 적합하다.
kind=barh로 하면 수직 / 수평 역전가능 !

4 : 히스토그램
변수 하나인 단변수 데이터의 빈도수를 그래프로 표현한다.
x축을 같은 크기의 여러 구간으로 나누고 각 구간에 속하는 데이터 값의 개수를 y축에 표시함.!
5: 산점도
서로 다른 두 변수 사이의 관계를 나타낸다.
mpg 데이터로 산점도 그래프를 그려보자.

# cylinders 개수의 상대적 비율을 계산하여 시리즈 생성
cylinders_size = df.cylinders/df.cylinders.max() * 300
# 3개의 변수로 산점도 그리기
df.plot(kind='scatter',x = 'weight', y = 'mpg', marker='+', figsize=(10,5),
cmap = 'viridis', c=cylinders_size, s=50, alpha=0.3) # 실린더 사이즈 값
plt.title('Scatter Plot : mpg-weight-cylinders')
plt.show()
plt.savefig('C:\\Users\\woghk\\OneDrive\\바탕 화면\\스터디\\판다스 자료실\\part3\/저장파일.png')
plt.savefig('C:\\Users\\woghk\\OneDrive\\바탕 화면\\스터디\\판다스 자료실\\part3\/저장파일(투명).png', transparent=True)
plt.show()
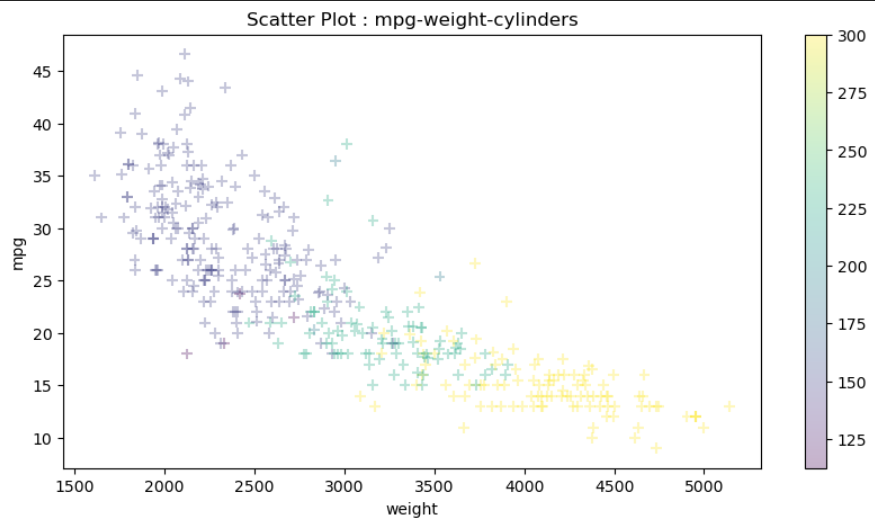
cmap = 컬러 설정 ( 종류가 엄청 많지만 cmap = 'viridis' 만 쓰자.)
5: 파이 차트
원을 파이처럼 나눠서 표현.
비율을 한눈에 볼 수 있다는 장점
6: 박스 플롯
범주형 데이터의 분포를 파악하는데 적합하다
# 박스 플롯
df = pd.read_csv("C:\\Users\\woghk\\OneDrive\\바탕 화면\\스터디\\판다스 자료실\\part3\/auto-mpg.csv",header=None)
print(df.head())
#열 이름 지정
df.columns = ['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
from matplotlib import font_manager, rc
font_path = "C:\\Users\\woghk\\Downloads\\nanum-all\\나눔 글꼴\\나눔고딕\\NanumFontSetup_TTF_GOTHIC\/malgun.ttf"
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family = font_name)
plt.style.use('seaborn-poster')
plt.rcParams['axes.unicode_minus']=False
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.boxplot(x=[df[df['origin']==1]['mpg'], # 위에 origin = 1 미국, 2: 영국, 3: 일본
df[df['origin']==2]['mpg'], # 미국[연비]....
df[df['origin']==3]['mpg']],
labels = ['USA','EU','JAPAN'])
ax2.boxplot(x=[df[df['origin']==1]['mpg'],
df[df['origin']==2]['mpg'],
df[df['origin']==3]['mpg']],
labels = ['USA','EU','JAPAN'],
vert=False)
ax1.set_title('제조국가별 연비 분포(수직 박스 플롯)')
ax2.set_title('제조국가별 연비 분포(수평 박스 플롯)')
plt.show()
# 박스플롯에서 평균을 볼 수 없다. 주황색은 중간값
# 동그라미는 이상값??
주황색 중간값
맨 위 맨 아래 : 최소, 최대값
박스의 끝 : 1분위, 3분위 값
고급 그래프 ( seaborn 활용 )
seaborn = matlpot의 기능 스타일 확장 버전이다.
회귀선이 있는 산점도
regplot() 서로 다른 2개의 연속 변수 사이의 산점도를 그리고 선형회귀분석에 의한 회귀선을 함께 나타낸다.
fit_reg = False 옵션을 설정하면 회귀선을 안 보이게 할 수 있다.
## regplot() 함수 = 서로 다른 2개의 연속 변수 사이의 산점도를 그리고 선형회귀 분석에 의한 회귀선을 나타냄.
# fig_reg = False 하면 회귀선 안보이게 할 수 있다.
import matplotlib.pyplot as plt
import seaborn as sns
# 스타일 테마 ( darkgrid, whitegrid, dark, white, ticks)
sns.set_style('darkgrid')
# 그래프 객체 생성
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
# 그래프 = 선형회귀선 표시 (fit_reg = True)
sns.regplot(x='age',
y='fare',
data = titanic,
ax= ax1)
# 그래프 = 선형회귀선 표시 X (fit_reg = False)
sns.regplot(x = 'age',
y = 'fare',
data = titanic,
ax = ax2,
fit_reg = False)
plt.show()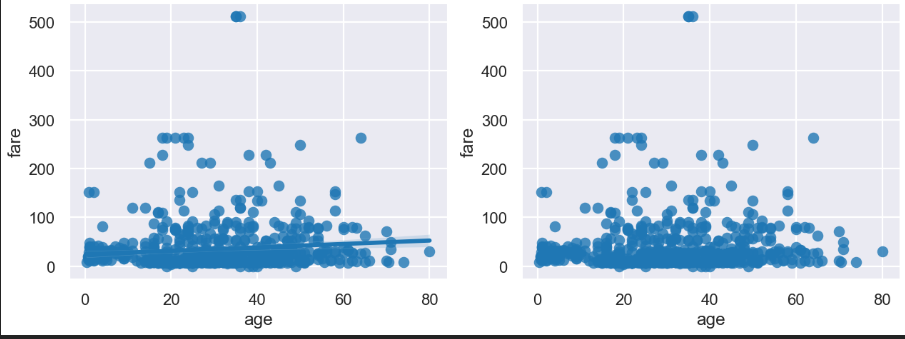
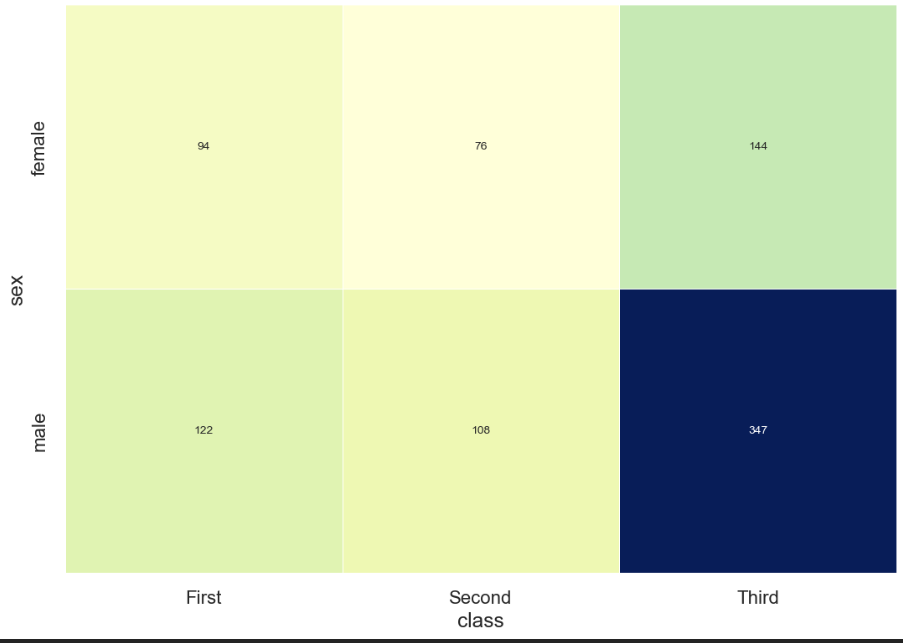
히트맵
히트맵으로 상관관계를 표현하기도 좋음!
table = titanic.pivot_table(index=['sex'], columns = ['class'], aggfunc = 'size')
#히트맵 그리기
sns.heatmap(table,
annot = True, fmt = 'd',
cmap = 'YlGnBu',
linewidth = .5,
cbar = False)
plt.show()
범주형 데이터의 산점도
stripplot() 과 swarmplot()이용
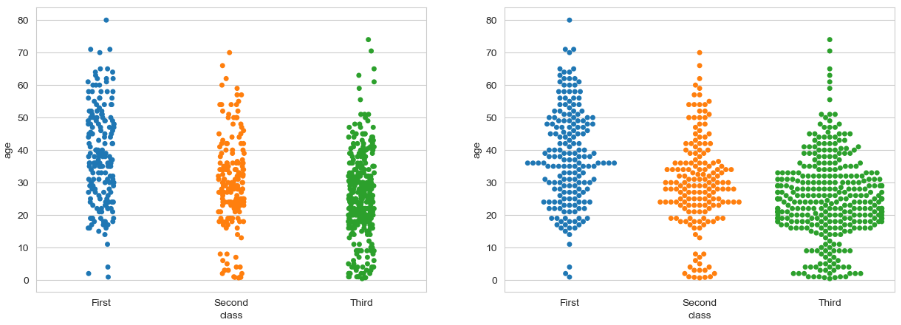
기존에 범주형 데이터면 stripplot을 애용했지만
분산까지 보여주는 swarmplot()을 쓰도록 하자!!!
조인트 그래프
jointplot() => 산점도를 기본으로 표시하고, 히스토그램을 동시에 보여줌