키워드: 오버피팅, 손실함수 ( 오차제곱합 , 교체 엔트로피 오차), 미니배치 학습, 미분/기울기 개념
신경망의 특징은 데이터를 보고 학습할 수 있다는 것이다.
데이터를 통해 학습한다는 것은 가중치 매개변수의 값을 데이터를 보고 결정한다는 뜻이다.!
신경망 층을 깊게 만든다면 매개변수가 n억개~일텐데 어떻게 학습하여 값을 조정하는지 그 원리에 대해서 알아보자.
먼저 숫자 5에 대한 이미지를 살펴보자.

사람마다 필체가 다르고, '5'라고 생각하는 사람마다의 기준이 다르다.
따라서 컴퓨터에게 '5'를 인식할 수 있도록 알고리즘을 설계할 수 도 있지만,
주어진 데이터를 잘 활용하여 해결할 수 있지 않을까? 라는 의문을 갖게 한다.
실제로 이미지에서 특징을 추출하고 그 특징의 패턴을 기계학습 기술로 학습하는 방법이 있다.
여기서 말하는 특징은 입력데이터(입력이미지)에서 본질적인 데이터를 정확하게 추출할 수 있도록 설계된 변환기를 가르킨다.
이미지의 특징은 주로 벡터로 기술하고, CV분야에서는 SIFT, SURF, HOG 등의 특징을 많이 사용한다.
이런 특징을 사용하여, 이미지 데이터를 벡터로 변환하고, 변환된 벡터를 가지고
지도학습의 대표적인 SVM, KNN 등으로 학습할 수 있다.
그림을 통해 이해하자!!!!
흰색 부분은 사람의 개입이 있고, 회색부분은 사람의 개입없이 소프트웨어 스스로 학습하는것을 의미한다.
손실 함수
보통 딥러닝에서, 모델의 성능을 평가하는 지표로 '손실 함수'를 사용한다.
이 손실 함수는 임의의 함수를 사용할 수 도 있지만 일반적으로는 오차제곱합(SSE)과 교차엔트로피 오차(CEE)를 사용
오차제곱합 (sum of squares for error)
위 식에서 Yk=신경망의 출력 (예측값)
Tk=정답데이터 (레이블)
k = 데이터 차원 수 (개수 x)
교차 엔트로피 오차 ( cross-entropy error , CEE )
tk, yk는 위와 같으므로
E = - ∑ (정답데이터 x log 예측값)
정답레이블 = 원핫인코딩이므로 ex ) [ 0,1,0,0,0,0 ] 직관적으로 볼 때 오답일 경우 (0) 값은 0, 정답일 경우에만 값이 존재함
따라서 정답일 때의 출력이 전체 값을 결정함.
+ 로그함수를 그래프로 그리면 x=1일때 y는 0이 되고 x가 0이랑 가까워질수록 값이 매우 작아짐.
--->위의 식도 마찬가지로 정답에 가까워질수록 0에 다가가고, 오답일경우(오답에 가까운경우)
교차 엔트로피 오차는 커진다.
def cross_entropy(y, t):
delta = 1e-7
return -np.sum(t*np.log(delta + y))코드를 잘 보면 로그 계산식 안에 아주 작은값 delta가 더해져 있는데,
이는 log 0 = 무한대이므로 이를 방지하기 위한 장치임을 알 수 있다.
t=정답레이블이고, 2가 정답이라고 하자
y=예측값이고, 2에 대한 예측이 0.6이다.
t = [ 0, 0, 1, 0, 0 ,0 ,0 ,0 ,0 ,0 ]
y = [0.1, 0.05, 0.6, 0 ,0.05, 0.1, 0, 0.1, 0 , 0 ]
cross_entropy(np.array(y),np.array(t))
0.510825457099338교차 엔트로피 오차는 0.51이 나온것을 확인할 수 있다.
반대로 틀렸다고 해보자!! (정답을 6이라고 예측한 경우)
y = [0.1, 0.05, 0.1, 0 ,0.05, 0.1, 0, 0.6, 0 , 0 ]
cross_entropy(np.array(y),np.array(t))
2.302584092994546값이 2.3이 출력된 것을 알 수 있다.
오답일경우 값이 크게 출력되는것을 확인할 수 있다.
미니배치 학습
우리가 앞에서 해본 MNIST 데이터set은 개수가 60,000개였다.
실무에서 딥러닝을 하게 되면, 이보다 훨씬 많은 빅데이터를 다루게 되는데, 이는 효율성, 시간적 측면에서 매우 비효율적이다.
따라서 드롭아웃, 미니배치 학습 등의 개념이 등장한다.
미니배치 학습은 말그대로 데이터 중 일부만 가지고 학습하는 것을 말한다.
이렇게 학습한 결과를 통해서 모델 전체의 '근사치'로 이용할 것이다.
import sys, os
sys.path.append(os.pardir)
from mnist import load_mnist
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=False)
print(x_train.shape)
print(t_train.shape)
(60000, 784)
(60000,)앞에서처럼 다시 MNIST 데이터셋을 불러오자,
이후 이 데이터에서 랜덤으로 10개만 불러오자.
train_size = x_train.shape[0]
batch_size= 10
batch_mask= np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
np.random.choice(10000,10)
array([3241, 3271, 1538, 3602, 1414, 7328, 3428, 7021, 5979, 5607])
아래 코드)미니배치용 교차엔트로피 함수
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t*np.log(1e-7 + y)) / batch_sizey가 1차원이라면 ( = 데이터 하나당 엔트로피 오차를 구하는 것) reshape함수로 데이터를 바꿔줌.
이후 배치 사이즈로 나눠서 정규화하고 이미지 1장당 평균의 교차 엔트로피 오차를 계산.
정답 레이블이 원-핫 인코딩이 아닌 '2'나 '6'등 숫자 레이블로 주어졌을 경우에는 다음의 코드로 살짝 수정한다.
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size이 구현은 원-핫 인코일 때 t가 0인 원소는 교차 엔트로피 오차도 0이므로, 그 계산은 무시해도 좋다는 뜻이다.
(정답에 해당하는 출력값만으로 교차엔트로피 오차를 구하겠다는 뜻)
그래서 np.log(y[np.arange(batch_size), t] )로 바꾼것이다.
참고) np.arange(batch_size) = 0부터 batch_size-1까지 배열을 생성한다.
즉, batch_size 5면 0부터 4까지 [0,1,2,3,4]를 만듬.
왜 손실함수를 사용할까
딥러닝 모델의 성능의 지표로 정확도가 더 적합해 보이지 않나? 라고 생각할 수 있다.
이를 설명하기 위해 먼저 '미분'의 개념이 필요하다.
신경망 학습에서 최적 매개변수 (가중치 / 편향)를 탐색할 때는 손실함수의 값을 가능한 한 작게 하는 매개변수의 값을 찾음
이때 매개변수의 기울기 (미분)을 계산하고, 그 미분값을 기준으로(단서로 삼아) 파라미터를 조정해 나가는것이다.
손실 함수의 미분값이 음수이면 가중치 매개변수를 양의 방향으로 변화시켜 손실 함수의 값을 줄일 수 있다.
반대로 미분값이 양수면 가중치 매개변수를 음수로 변화시켜 손실함수의 값을 줄일 수 있다.
반대로 미분값이 0이면 가중치 매개변수를 어느쪽으로 움직여 손실함수의 값은 줄어들지 않는다.
그래서 학습(?)이 종료된다. (원리 )
정확도를 성능의 지표로 삼지않는것은 대부분의 점에서 미분값이 0이나오기 때문이다.
--> 100개의 사진중 32개만 맞추면 정확도가 32%이다. 여기서 가중치 매개변수를 조금 바꾼다고 해도 정확도는 거의 바뀌지 않는다. + 바뀐다 하더라도 35, 29 등 불연속적으로 바뀌게 된다.
하지만 손실 함수의 경우 연속적인값이 나온다. ex) 0.87634756... 그리고 변수값을 조금 변하면 그에 반응하여 손실 함수의 값 0.85323.. 처럼 연속적으로 변화하는것이다.
정확도는 매개변수의 미세한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속으로 갑자기 변화한다.
이는 계단 함수를 활성화함수로 사용하지 않는 이유와도 같다.
만약 계단 함수를 활성화함수로 사용한다면 위와 같은 이유로 모델이 좋은 성능을 낼 수 없다.
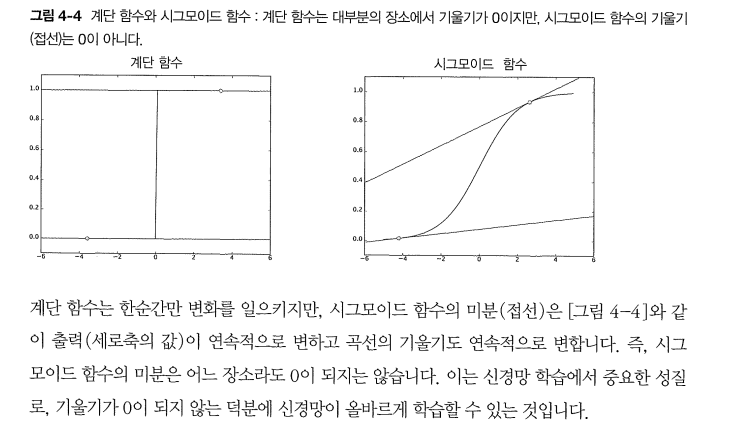
따라서 위 그래프에서, 계단 함수를 활성화함수로 사용하면 안되는 이유를 알 수 있다.
한 지점 의외 값은 모두 0이므로 계단 함수를 손실 함수로 사용하면 안된다!
미분
미분 = (특정) 순간의 변화량
df(x)/dx = lim h->0 f(x+h) - f(x) / h
이를 곧이 곧대로 구현을 한다면 다음과 같다.
def numerical_diff(f,x):
h = 10^-4
return (f(x+h) - f(x)) / h얼핏보면 문제가 없어 보이지만, 개선해야할 부분이 있다.
함수 f의 차분이다. (두 점에 함수 값의 차이)
진정한 미분은 x의 위치에서의 기울기(접선)이지만, 위의 식은 x+h와 x 사이의 기울기를 의미한다. (h가 완전한 0이 아님)
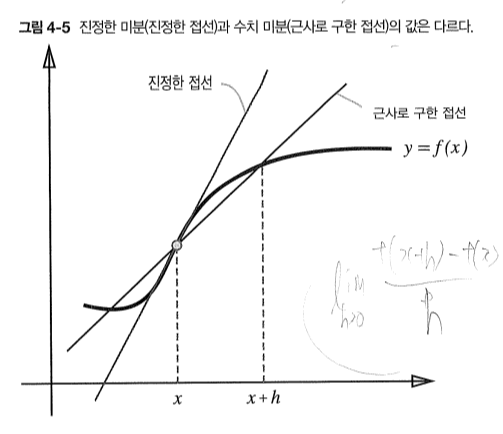
위 그림과 같이 오차가 발생하게 된다. 위는 전방 차분
이 오차를 줄이기 위해 (x+h)와 (x-h)일 때의 함수의 차분을 계산하는 방법을 쓰기도 한다. 이를 중심/중앙 차분이라고 한다!
def numerical(f,x):
h = 1e-4
return (f(x+h)-f(x-h)) / 2*h
편미분
f(x, y) = x^2 + y^2이 있다고 하자.
이 식은 다음과 같이 구현할 수 있다.
def funct_2(x):
return x^2 + y^2
# x = 배열이 함수의 그래프를 그려보면 다음과 같이 3차원 그래프로 나온다.
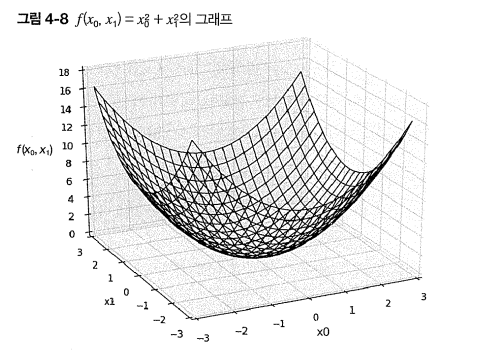
이제 위의 식을 미분해보자. 변수가 2개라서 어느 변수에 대한 미분인지 구별해야한다.
따라서 편미분이 필요하다.
x0 = 3, x1= 4일때, x0에 대한 편미분 ∂f/∂x0를 구하라.
def function_tmp1(x0):
return x0 * x0 + 4.0 **2.0
print(numerical_diff(function_tmp1,3.0))
6.00009999999429def function_tmp2(x1):
return 3**2 + x1*x1
print(numerical_diff(function_tmp2, 4.0))
8.00009999998963
위 문제들은 변수가 하나인 함수를 정의하고, 그 함수를 미분하는 형태로 구현해서 풀었다.
이처럼 편미분은 변수가 하나인 미분과 마찬가지로 특정 장소의 기울기를 구한다.
'밑바닥 딥러닝' 카테고리의 다른 글
| Ch 5-2 오차 역전파 (Error BackPropagation) (0) | 2023.05.27 |
|---|---|
| Ch 5-1 오차 역전파 ( Error Backpropagation ) (0) | 2023.05.27 |
| Ch4-2 신경망 학습 (0) | 2023.05.26 |
| Ch3-2 출력층 설계, 실습 (0) | 2023.05.17 |
| Ch3-1 신경망 (0) | 2023.05.17 |