학습률을 서서히 낮추는 가장 간단한 방법은 "전체"의 학습률을 값을 일괄적으로 낮추는 것이다.
이를 더욱 발전시킨 것이 AdaGrad이다.
Adagrad는 전체에서 발전해 "각각"의 매개변수에 맞게 갱신해준다.
'적응적 학슙를'을 기반으로 한 옵티마이저이다.
Adagrad, RMSprop = 적응적 학습률 기반
momentum이라는 개념을 이용하여 gradient를 조절
어떻게 개별 매개변수마다 갱신을 해줄까? 자세히 알아보자.
위 수식에서 h는 기존 기울기값을 제곱하여 계속 더해준다.
그리고 매개변수를 갱신할 때 1/ √h를 곱해서 학습률을 조정한다.!!
이 뜻은 매개변수 원소 중에서 많이 움직이는 원소는 학습률이 낮아진다는 뜻이라고 볼 수 있다.
(다시 말해 학습률 감소가 매개변수 원소마다 다르게 작용됨.)
손코딩
classAdaGrad:def__init__(self, lr=0.01):
self.lr = lr
self.h = Nonedefupdate(self, params, grads):if self.h inNone:
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
parmas[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
주의) 마지막 줄에서 1e-7를 더해주는 부분. 1e-7은 self.h[key]에 0이 담겨 있어도 0으로 나누는 것을 막아줌.
Adagrad의 갱신경로를 그림으로 보자.
최소값을 향해 효율적인 움직임을 보여준다.!!
6.1.6 아담 ( Adam )
모멘텀은 공을 구르는 듯한 움직임을 보여준다. Adagrad는 원소 개별적으로 갱신해주었다.
이 둘을 합치면 Adam이라고 할 수 있다.
그림을 먼저 보자.
모멘텀과 비슷한 패턴이지만, 좌우 흔들림이 적은 것을 볼 수 있다.
이는 학습의 갱신 강도를 적응적으로 조정해서 얻는 benefit이라고 한다.
마지막으로 정리해서 봐보자.
무엇이 제일 좋다!! 라는 것은 데이터, 목적, 그 밖의 하이퍼 파라미터에 따라 다르기 때문에 정해진 것이 없다.
하지만 통상적으로 SGD보다 momentum,adam,adagrad 3개가 더 좋고, 일반적으로 Adam을 많이 쓴다고 한다.
6.2 가중치의 초기값
신경망 학습에서 가중치 초기값이 매우 중요하다고 한다.
2절에서는 권장 초기값을 배우고 실제로 학습이 잘 이루어지는지 확인해보자.
6.2.1 초기값을 0으로 하면?
이제부터 오버피팅을 억제해 범용 성능을 높이는 테크닉인 가중치 감소 기법을 소개해주겠다.
가중치 감소는 가중치 매개변수의 값이 작아지도록 학습하는 방법이다.
가중치 값을 작게 해서 오버피팅을 일어나지 않도록 하게 하는 것이다.
가중치 값을 작게 만들고 싶으면 초기값도 최대한 작은 값에서 시작하는 것이 정공법이기 때문에,,!
사실 지금까지 가중치 초기값은 0.01 * np.random.randn(10,100)처럼 정규분포에 생성된 값에 0.01배를 한 작은값을 사용
했었다.
그렇다면 가중치 초기값을 모두 0으로 설정하면 어떨까??
결론부터 말하자면, 아주 안좋은 생각이다.
실제로 가중치 초기값을 0으로 하면 학습이 올바로 이루어지지 않는다.
오차역전파법에서 모든 가중치의 값이 똑같이 갱신되기 때문이다.
예를 들어 2층 신경망에서 첫 번째, 두 번째 층의 가중치가 0이라고 가정해보자.
그럼 순전파 때는 입력층의 가중치가 0이기 때문에 두 번째 층의 뉴런에 모두 같은 값이 전달된다.
두 번째 층의 모든 뉴런에 같은 값이 입력된다는 것은 역전파 두 번 층의 가중치가 모두 똑같이 갱신된다는 말과 같다.
(곱셈 노드의 역전파를 기억해보자.)
그래서 가중치들을 같은 초기값에서 시작하고 갱신을 거쳐도 여전히 같은 값을 유지하는 것이다.
이는 가중치를 여러 개 갖는 의미를 사라지게 한다.
이 '가중치가 고르게 되어버리는 상황'을 막으려면 초기값을 무작위로 설정해야 한다.
6.2.2 은닉층의 활성화값 분포
은닉층의 활성화값(활성화 함수의 출력 데이터)의 분포를 관찰하면 중요한 정보를 얻을 수 있었다.
이번 절에서는 가중치의 초기값에 따라 은닉층 활성화 값들이 어떤 분포를 갖는지 시각화 해보려한다.
예시로 5층의 신경망을 가정, 시그모이드 함수 사용, 입력데이터 무작위로 선정
import numpy as np
import matplotlib.pyplot as plt
defsigmoid(x):return1 / (1 + np.exp(-1))
x = np.random.randn(1000, 100) # 1000개의 데이터
node_num = 100# 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5# 은닉층이 5개
activations = {} # 이 곳에 활성화 결과(활성화값)를 저장
fro i inrange(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z
층은 5개, 각 층의 뉴런은 100개씩이다.
활성화 값들의 분포를 그려보자.
# 히스토그램 그리기for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + '-layer')
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()
각 층의 활성화 값들이 0과 1에 치우쳐져 있다.
시그모이드 함수는 출력이 0또는 1에 가까워지면 미분값은 0에 수렴한다.
따라서 데이터가 0과 1에 치우쳐 분포하게 되면 역전파 기울기 값이 점점 작아지다가 사라진다.
이를 기울기 소실 현상 ( gradient vanishing )이라고 한다.
이제 표준편차를 0.01로 바꿔서 다시 그려보면 다음과 같은 그래프를 얻을 수 있다.
아까와 같은 기울기 소실 문제는 보이지 않지만, 모두 중간값에 몰빵되있는 것을 볼 수 있다.
이는 표현력 관점에서 문제라고 볼 수 있다.
Xavier 초기값
사비에르 초기값이란 사비에르가 작성한 논문에서 발췌한 것으로, 현재까지 딥러닝 프레임워크에서 많이 사용한다.
.신경망의 순전파에서는 가중치 총합의 신호를 계산하기 위해 행렬 곱을 사용했다 ( np.dot )
그리고 행렬 곱의 핵심은 원소 개수 (차원 개수)를 일치시키는 것이다.
예시를 통해 그림으로 이해해보자. (계산 그래프)
X,W,B가 있다고 하자. 각각 입력, 가중치, 편향이고 shape은 각각(2,) , (2,3), (3,)이다.
X와 W가 들어와 np.dot을 통해 행렬 곱 수행 -> x * W -> ( x * W ) +B = Y
이제 역전파를 알아보자.
아래 식이 도출되는것을 확인하자.
WT는 T의 전치행렬을 말함.
(전치행렬 = Wij 를 Wji로 바꾼것. 아래 그림 참조)
위 식을 통해서 계산 그래프의 역전파를 구해보자.
위 그림의 네모 박스 1,2를 유심히 살펴보자. (덧셈노드는 그대로 흐르고, 곱셈 노드는 교차하므로 !!)
X,W,B의 shape은 각각(2,) , (2,3), (3,)이다.
∂L/∂Y는 (3,) 인데 W인 (2,3)과 차원이 달라 곱셈이 되지 않는다.
따라서 WT를 통해 (3,2)로 바꿔 곱셈을 수행할 수 있도록 변환 (+X도 마찬가지)
5.6.2 배치용 Affine 계층
지금까지 예시로 든것은 X (입력 데이터)가 하나일 때만 고려한 상황이였다.
하지만 현실에서는 하나일 확률이 매우 적으므로 실제 Affine 계층을 생각해보자.
입력 데이터가 N개일 경우이다.
5.6.3 Softmax-with-Loss 계층
마지막으로 배울 것은 출력층에서 사용하는 소프트맥스 함수이다.
딥러닝에서는 학습과 추론 두 가지가 있다.
일반적으로 추론일 때는 Softmax 계층(layer)을 사용하지 않는다. Softmax 계층 앞의 Affine 계층의 출력을 점수(score)라고 하는데, 딥러닝의 추론에서는 답을 하나만 예측하는 경우에는 가장 높은 점수만 알면 되므로 Softmax 계층이 필요없다. 반면, 딥러닝을 학습할 때는 Softmax 계층이 필요하다.
이제 소프트맥스 계층을 구현할텐데, 손실 함수인 엔트로피 오차도 포함하여 계산 그래프를 살펴보자.
너무 복잡하다. 간소화 해보자.
여기서는 3클래스 분류를 가정하고 이전 계층에서 3개의 입력(점수)를 받는다.
그림과 같이 Softmax 계층은 입력 a1,a2,a3를 정규화하여 y1,y2,y3를 출력함
앞에서는 입력층-> 은닉층 -> 출력 순으로 가중치를 업데이트 했었다. 이를 순전파라고 한다.
오차 역전파 방법은 순전파에서 생기는 결과값의 오차를 다시 역순으로 보낸 후, 가중치를 재계산하여 오차를 줄여나간다.
더 정확히 얘기하면, 기존의 방식은 수치 미분을 통해 기울기를 구하지만, 계산 시간이 오래걸린다는 단점이 있다.
하지만 오차 역전파 방식은 손실함수의 기울기를 더 효율적으로 계산하기 위해 쓰인다고 볼 수 있다.
(가중치 매개변수에 대한 손실함수의 기울기)
오차 역전파 방식을 그림으로 이해해보자.!
5.1.1 계산 그래프
문제 1) 재환이는 슈퍼에서 개당 100원인 사과를 두 개 샀다. 이 때 지불금액을 구해라. 소비세는 10%
문제 2)재환이는 슈퍼에서 개당 100원인 사과를 두 개, 개당 150원인 귤을 세 샀다. 이 때 지불금액을 구해라.
소비세는 10%
문제 1과 2을 계산 그래프로 푼다면 다음 그림과 같다.
이렇게 계산 방향이 왼쪽 -> 오른쪽으로 전달되어 진행되는 과정을 순전파라고한다.
역전파는 물론 순전파의 반대 개념이다.!!
그 전에, 더 알아볼 개념이 있다.
5.1.2 국소적 계산
계산 그래프의 특징은 '국소적 계산'을 전파함으로 최종 결과를 얻는다는 점에 있다.
'국소적' 이란 '자신과 직접 관계 되있는 작은 범위'를 말한다.
국소적 계산은 결국 전체에서 어떤 일이 벌어지든 상관없이 자신과 관계된 정보만으로 결과를 출력할 수 있다는 것이다.
구체적인 예시를 통해 알아보자.
가령 슈퍼에서 사과를 포함한 여러 식품을 구매한다고 했을 때는 아래 그림 같다.
그림에서, 여러 식품의 구매가격이 4,000원이 나왔다. 여기서 핵심은 각 노드의 계산이 국소적이라는 것이다.
즉, 무엇을 얼마나 샀는지 (계산이 얼마나 복잡한 지)와 상관없이 두 숫자만 더하면 된다는것( 4,000 + 200)
이처럼 계산 그래프는 국소적 계산에만 집중하면 된다.
5.1.3 왜 계산 그래프로 푸는가?
첫 번째 답은 국소적 계산의 이점 때문이다.
즉, 아무리 계산 과정, 방법이 복잡해도 노드 계산에만 집중해서 문제를 해결할 수 있다는 점이다.
두 번째 답은 역전파를 통해 '미분'을 효율적으로 계산할 수 있기 때문이다.
이제 역전파를 이해하기 쉽게 위 문제를 다시 보자.
문제 1은 사과 두 개 사서 최종 가격을 구하는 것이였다.
여기서 만약 사과 가격이 오르면 최종 금액이 얼마나 변할 지 알고 싶다고 해보자.
이는 사과 가격에 대한 지불금액의 미분값을 구하는 것과 같다.!!
기호로 나타낸다면 ∂L/∂x ( L = 최종금액, x = 사과 가격)
문제를 풀어본다면 다음 그림과 같다.
문제1을 예시로 한 설명
역전파는 순전파와 반대 방향의 굵은 화살표 그림
역전파는 국소적 미분 전달하고, 미분 값은 화살표의 아래에 표시 ( 위 그림에서는 빨간 글씨 )
★ 사과가 1원 오르면 최종 금액은 2.2원 오른다는 의미 ★
소비세에 대한 지불 금액의 미분이나 사과 개수에 대한 지불 금액의 미분도 같은 순서로 구할 수 있음
중간까지 구한 미분 결과가 공유가 가능하기 때문에 다수의 미분을 효율적 계산이 가능함
계산 그래프의 이점은 순전파와 역전파를 활용해 각 변수의 미분을 효율적으로 구할 수 있음
5.2 연쇄법칙
위의 역전파 방식은 국소적 미분을 전달하는 것이고, 전달하는 원리는 연쇄법칙을 따른 것이다.
5.2.1 계산 그래프의 역전파
위 그림과 같이 역전파의 계산 절차는 신호 E에 노드의 국소적 미분(∂y/∂x)를 곱한 후 다음 노드로 전달하는 것이다.
방금 말한 국소적 미분은 순전파 때의 y=f(x) 계산의 미분을 구한다는 뜻이며, 이는 x에 대한 y의 미분을 구한다는 것이다.
이러한 방식이 역전파의 계산 순서인데, 이 방식이 목표로 하는 미분값을 효율적으로 구할 수 있다는것이 역전파의 핵심임.
5.2.2 연쇄법칙이란?
연쇄 법칙은 합성 함수부터 시작해야 한다.
합성 함수란 여러 함수로 구성된 함수로, 연쇄법칙은 합성 함수의 미분에 대한 성질과 같다.
또한합성 함수의 미분은 합성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다.
이게 연쇄법칙의 원리이다.
ex) z = (x + y)^2라는 식은 z=t^2 과 t=x+y 두 개의 식으로 구성된다.
이 두 개의 식을 각각 t에 대해서 미분을 하면 2t, 1이다. 그리고 이 둘을 곱하면 아래 식(그림)과 같다.
위 그림을 보자.
계산 그래프의 역전파는 오른쪽에서 왼쪽으로 진행한다고 했었다.
역전파의 계산 절차는 노드로 들어온 입력 신호에 그 노드의 국소 미분(편미분)을 곱한 후 다음 노드로 전달한다.
위에서 **2 노드에서 역전파를 살펴보자. 입력은 ∂z/∂z이며 이에 국소적 미분인 ∂z/∂t를 곱한 후 다음 노드로 넘긴다.
주목할 것은 맨 왼쪽 역전파이다. 이 계산은 연쇄법칙에 따르면 'x에 대한 z의 미분'이 된다.
즉, 역전파는 연쇄법칙의 원리와 같다고 볼 수 있다.
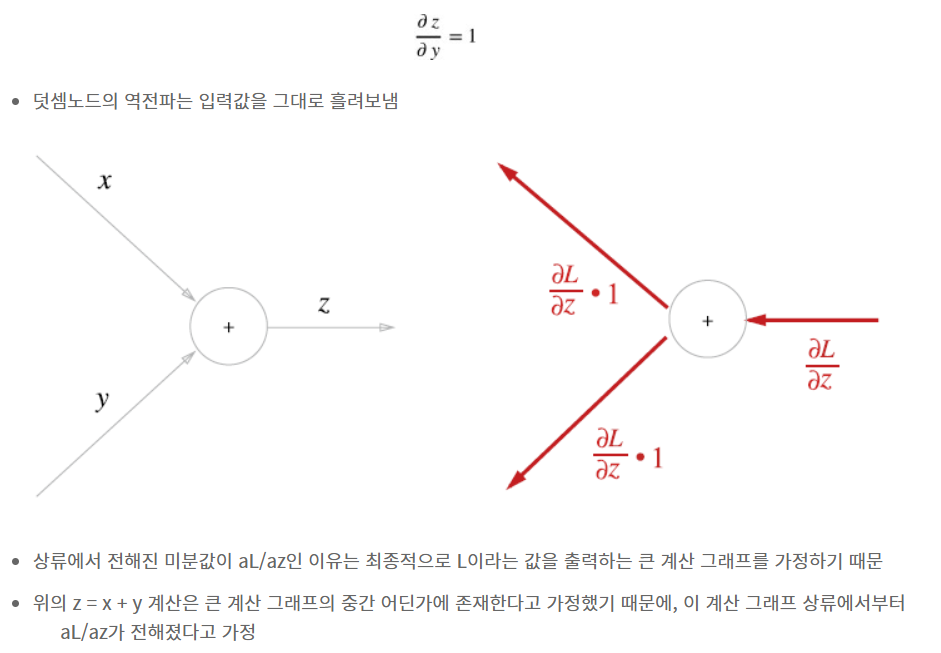
5.3.1 덧셈 노드의 역전파
z = x+ y 라는 식을 대상으로 역전파를 살펴보면, ∂z/∂x와 ∂z/∂y 모두 1이다 (분자 z를 각각 분모인 x,y로 미분하니까)
결론만 말하자면 덧셈 노드의 역전파는 입력 값을 그대로 흘려보낸다.
5.3.2 곱셈 노드의 역전파
z = x * y 라는 식을 가정해보자. 이 식의 미분은 ∂z/∂x = y , ∂z/∂y = x이다.
곱셈노드의 역전파는 상류의 값에 입력 신호들을 서로 바꾼 값을 곱해서 하류로 보낸다.
(서로 바꾼 값이란 순전파에서는 x였다면 y를, y였다면 x로 바꾼다는 의미)
아래 그림을 통해 이해
5.3.3 사과 쇼핑의 예
정리할 겸, 아래 그림을 통해 빈칸에 들어갈 값을 구해보자.
5.4 계층 구현하기
5.4.1 곱셈 계층
classMulLayer:def__init__(self):
self.x = None
self.y = Nonedefforward(self,x,y):
self.x = x
self.y = y
out = x * y
return out
defbackward(self, dout):
dx = dout * self.y # x와 y를 바꾼다
dy = dout * self.x
return dx, dy
__init__에는 인스턴스 변수인 x와 y를 초기화한다. 이 두 변수는 순전파 시의 입력값을 유지하기 위해 사용!!!
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.if p == t[i]
accuracy_cnt += 1
print("Accuracy: " + str(float(accuracy_cnt) / len(x)))
Accuracy: 0.9352
93.52%의 정확도를 나타낸다.
MNIST 데이터셋을 얻고 네트워크를 생성한다.
이어서 for문을 돌며 x에 저장된 사진을 한장 씩 꺼내서 predict()함수에 집어 넣는다.
predict() 함수는 각 레이블의 확률을 넘파이 배열로 반환한다.
예를 들어 [0.1, 0.8, 0.9 .... 0.1] 같은 배열이 반환되며 이는 각각이 인덱스(숫자 번호)일 확률을 나타낸다.
그 다음 np.argmax()함수로 이 배열에서 값이 가장 큰 ( 확률 제일 높은) 원소의 인덱스를 구한다.
이것이 바로 예측 결과 !
마지막으로 정답 데이터와 비교하여 맞힌 숫자를 count += 1씩 하고, count / 전체 이미지 수 로 나눠서 정확도를 구하는 것이다.