이번에 살펴본 RNN 구조는 두 개로 나누어, 하나는 인코더, 하나는 디코더로 명명한 후, 두 개의 RNN을 연결해서 사용하는 인코더-디코더 구조이다.
해당 인코더-디코더 구조는 "입력 문장"과 "출력 문장"의 길이가 다를 경우에 주로 사용한다.
대표적인 예시로 번역기/텍스트 요약이 있다.
(영어 -> 한국어로 번역 시 문장의 길이가 달라질 수 있으므로!
(원본 텍스트 -> 요약 -> 문장 수 감소 {문장 길이 변화})
1. 시퀀스-투-시퀀스 (Sequence-to-Sequence, seq2seq)
시퀀스-투-시퀀스는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용된다고 한다. (챗봇, 기계 번역등)
입력 시퀀스와 출력 시퀀스를 각각 질문&대답으로 구성하면 챗봇을 만들 수 있고, 각각 입력 문장&번역 문장으로 만들면
번역기로 만들 수 있는 것이다. 그 외에도 텍스트 요약이니ㅏ STT(speech to text)에서도 쓰일 수 있다고 함.

seq2seq는 번역기에서 대표적으로 사용되는 모델로, 딥 러닝의 '블랙 박스'에서 확대해가는 방식으로 설명한다.
이제 위 그림에서 i am a student에서 프랑스어로 변화하는 내부 과정을 살펴보자.

인코더와 디코더를 통해 변환되는데, 여기서 중요한 포인트가 있다.
인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 모든 단어 정보를 압축해서 하나의 벡터로 만드는데, 이를 컨텍스트 벡터라고 한다.
(입력 문장의 정보가 하나의 context vector로 모두 압축 -> 인코더는 context vector를 디코더로 전송! -> 디코더는 입력받은 context vector를 하나씩 순차적으로 출력하는 과정)

실제로 사용되는 seq2seq 모델에서는 context vector가 수백개의 차원을 갖고 있다고 한다. (그림에서는 4차원)
또한, 성능 이슈로 인해 실제로는 바닐라 RNN이 아닌, LSTM/GRU 셀로 구성한다고 함!
주황색 인코더를 자세히 보면, 입력 문장은 단어 토큰화를 통해서 단어 단위로 쪼개어지고, 단어 토큰 각각은 RNN 셀의 각 시점에서 입력이 된다. 인코더 LSTM 셀은 모든 단어를 입력받은 뒤 인코더 LSTM 셀의 마지막 시점의 은닉 상태를 디코더 RNN 셀로 넘겨주는데, 이게 contexet vector인 것이다! 따라서 context vector는 디코더 RNN 셀의 첫 번쨰 은닉 상태겠지?
이제 그림의 디코더의 LSTM 셀을 보면, <sos>라는 심볼을 볼 수 있다.
sos는 초기 입력으로 문장의 시작을 의미하는 심볼이라고 하고, 이게 입력되면 다음에 등장할 확률이 높은 단어를 예측함
여기서는 je라고 예측했다고 볼 수 있다. 그리고 이 je가 다음 셀의 입력으로 들어가서 또 예측을 진행, suis를 결과! (반복)
참고로 이것은 테스트 과정 동안의 프로세스를 나타낸다.
seq2seq는 훈련 과정과 테스트 과정의 작동 방식에 차이가 있다.
훈련 과정: context vector와 실제 정답을 동시에 가지므로, 지도 학습 방식을 통해 훈련함! = teacher forcing(교사 학습)
테스트 과정: 훈련 과정과 달리 오직 context vector와 sos 심볼만 입력받은뒤 예측 -> 결과 -> 예측 -> 결과 반복!!
알다 시피 기계는 텍스트보다 숫자 연산에 특화되어 있다. NLP는 기본적으로 tetx -> 벡터로 바꾸는 워드 임베딩을 주로 사용하고 있다 즉, seq2seq에서 사용되는 단어들은 모두 임베딩 벡터로 변환 후 입력으로 사용됨. 아래 그림은 임베딩 층임

(I, am, a student의 embedding layer)

현재 시점을 t라고 할 때, RNN셀은 t-1에서의 은닉 상태와 t에서의 입력 벡터를 입력으로 받고, t에서의 은닉 상태를 만든다.
이때 t에서의 은닉 상태는 바로 위에 또 다른 은닉층이나 출력층이 존재할 경우 위 층으로 보내거나, 필요없다면 무시 할 수있다. 그리고 RNN 셀은 다음 시점에 해당하는 t+1의 셀의 입력으로 현재 t에서의 은닉 상태를 입력으로 보낸다.
(현 시점 t의 은닉 상태는 과거 심저의 동일한 RNN 셀에서의 모든 은닉 값들에 영향을 누적해 받아온 값임)
2. seq2seq 코드 실습
seq2seq2 모델을 설계하고, teacher forcing을 사용하여 훈련시켜보자.

참고로, vocab size 변수에 대한 정보는 아래 그림과 같다.
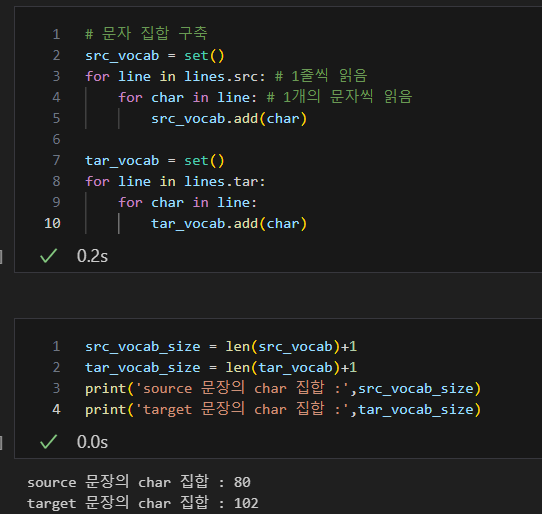
인코더 코드를 보자.
lstm의 은닉 상태 크기는 256
return_state = True -> 인코더의 내부 상태를 디코더로 넘겨주어야 하기 때문
LSTM에서 state_h, state_c를 리턴받는데, 이는 은닉 상태와 셀 상태에 해당한다.
이 두 가지 상태를 encoder_states에 저장한다.
그리고 encoder_states를 디코더에 전달함으로, 두 가지 상태 모두를 디코더로 전달하게 된다,! (이게 context vector)
디코더 코드)
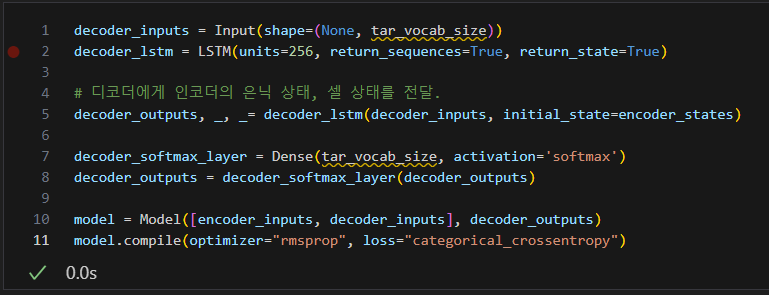
디코더는 인코더의 마지막 은닉 상태를 초기 은닉 상태로 사용한다.
위에서 initial_state의 인자값으로 encoder_states를 주는 코드가 이에 해당한다고 볼 수 있다.
또한 동일하게 디코더의 은닉 상태 크기도 256으로 설정
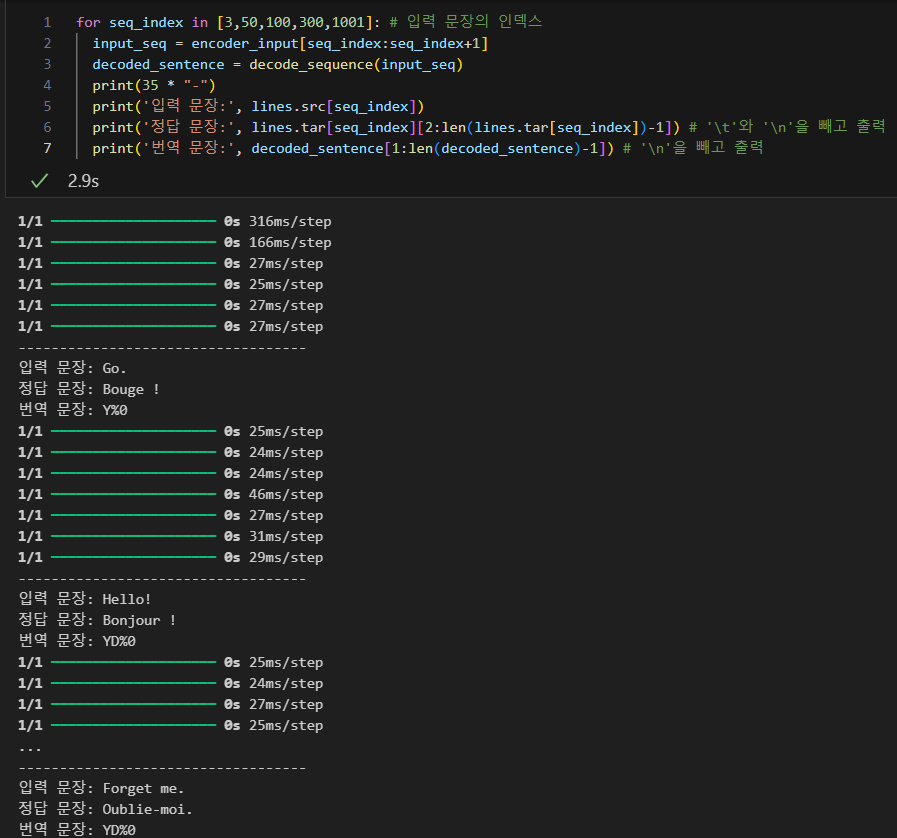
테스트(activate) 동작 설계
디코더를 설계해보자.
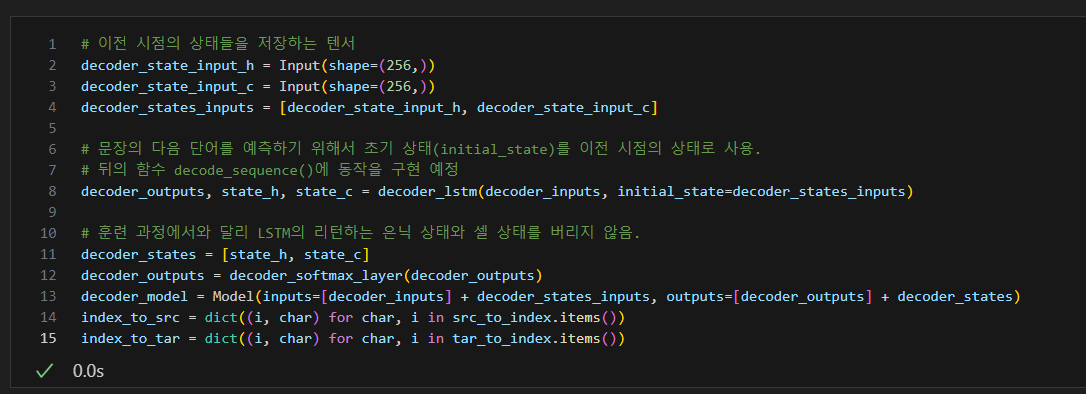
단어로부터 인덱스를 얻는 것이 아니라 인덱스로부터 단어를 얻을 수 있는 index_to_src와 index_to_tar로 만들기
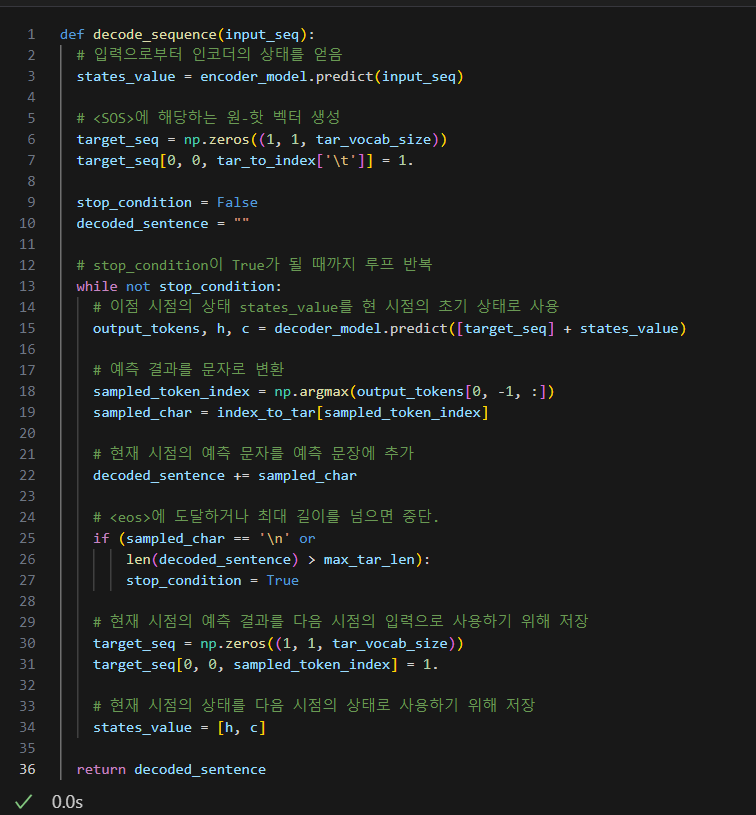
sdsd
'딥 러닝 > 자연어처리 - 텍스트 전처리' 카테고리의 다른 글
| 어텐션 메커니즘 (Attention Mechanism) (0) | 2024.07.13 |
|---|---|
| 6. 정수 인코딩(Integer Encoding) (0) | 2024.03.09 |
| 5. 정규 표현식 (Regular Expression) (0) | 2024.03.09 |
| 정규 표현식 (Regular Expression) (0) | 2024.03.09 |
| 4. 불용어 처리 (Stopword) (0) | 2024.03.09 |