컴퓨터는 텍스트보다는 숫자를 더 잘 처리한다.
이를 위해 자연어 처리에서는 텍스트를 숫자로 바꾸는 여러가지 기법들이 있다. 그리고 그러한 기법들을 본격적으로 적용시키기 위한 첫 단계로 각 단어를 고유한 정수에 맵핑(mapping)시키는 전처리 작업이 필요함.
예를 들어 갖고 있는 텍스트에 단어가 5,000개가 있다면, 5,000개의 단어들 각각에 1번부터 5,000번까지 단어와 맵핑되는 고유한 정수. 다른 표현으로는 인덱스를 부여합니다. 가령, book은 150번, dog는 171번, love는 192번, books는 212번과 같이 숫자가 부여됩니다.
인덱스를 부여하는 방법은 여러 가지가 있을 수 있는데 랜덤으로 부여하기도 하지만, 보통은 단어 등장 빈도수를 기준으로 정렬한 뒤에 부여합니다. ("빈도수 기준" -> 허프만 알고리즘 같다.)
정수인코딩 = 단어를 정수와 매핑 = 빈도수 기준 !
1. 정수 인코딩(Integer Encoding)
단어에 정수를 부여하는 방법 중 하나로 단어를 빈도수 순으로 정렬한 단어 집합(vocabulary)을 만들고, 빈도수가 높은 순서대로 차례로 낮은 숫자부터 정수를 부여하는 방법이 있다.
이해를 돕기위해 단어의 빈도수가 적당하게 분포되도록 의도적으로 만든 텍스트 데이터를 가지고 실습해보겠습니다.
예제)
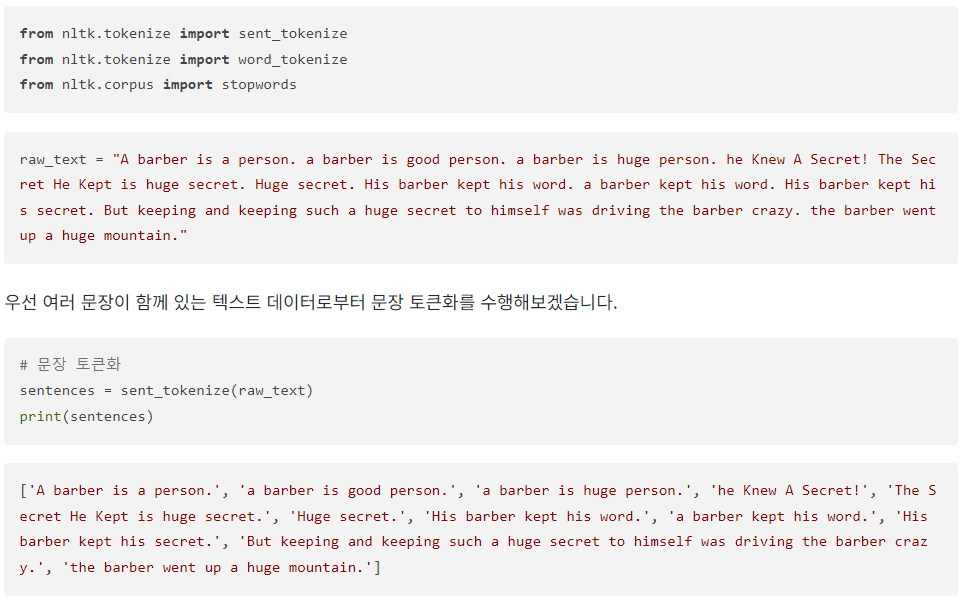
위 코드 -> 문장 단위로 토큰화 수행.
이제 앞으로는 정제 작업과 정규화 작업을 병행하며, 단어 토큰화를 수행.
여기서는 단어들을 소문자화하여 단어의 개수를 통일시키고, 불용어와 단어 길이가 2이하인 경우에 대해서 단어를 일부 제외.
텍스트를 수치화하는 단계라는 것은 본격적으로 자연어 처리 작업에 들어간다는 의미이므로, 단어가 텍스트일 때만 할 수 있는 최대한의 전처리를 끝내놓아야 한다는 점이 뽀인뜨
이에 따른 단어 토큰화 진행

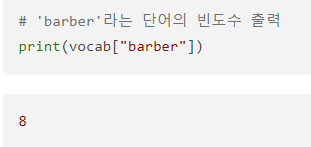
현재 vocab에는 각 단어에 대한 빈도수가 기록되어 있다. 출력해보자.

파이썬의 딕셔너리 구조로 단어를 키(key)로, 단어에 대한 빈도수가 값(value)으로 저장되어 있음.
vocab에 단어를 입력하면 빈도수를 리턴.
이제 빈도수가 높은 순서대로 정렬해보자.

높은 빈도수를 가진 단어일수록 낮은 정수를 부여한다! 정수는 1부터 부여

따라서 1의 인덱스를 가지는 단어가 가장 빈도수가 높다는 뜻이다.
스트에서 등장 빈도가 매우 낮은 단어의 경우는 의미가 없을 가능성이 농후하기 때문에, 제외하는 것이 국룰이다.
(등장 빈도가 낮다는 것 = 인덱스 num이 높다는 것!)
글 참조 : https://wikidocs.net/31766
'딥 러닝 > 자연어처리 - 텍스트 전처리' 카테고리의 다른 글
| 어텐션 메커니즘 (Attention Mechanism) (0) | 2024.07.13 |
|---|---|
| (RNN) 시퀀스-투-시퀀스(seq2seq) (2) | 2024.07.13 |
| 5. 정규 표현식 (Regular Expression) (0) | 2024.03.09 |
| 정규 표현식 (Regular Expression) (0) | 2024.03.09 |
| 4. 불용어 처리 (Stopword) (0) | 2024.03.09 |