오늘은 어려운 응용 문제 3가지를 풀어봅시다.
✅ 문제 1: 가입 → 첫 주문까지 30일 이내인 유저의 평균 지연일 & 상품군 분석
테이블
- users(user_id, signup_date)
- orders(order_id, user_id, order_date)
- order_items(order_id, item_id)
- items(item_id, category)
요구사항
- 각 카테고리(category) 별로,
- 가입 후 30일 이내 첫 구매한 유저만 집계
- 해당 유저들의 가입 → 첫 주문까지 평균 일수
- 카테고리, 가입월(signup_date) 기준으로 정리
첫 풀이)
WITH first_buyers AS (
SELECT user_id, MIN(order_date) AS order_date
FROM orders
GROUP BY user_id),
30_buyers AS(
SELECT A.user_id AS user_id, A.signup_date AS signup_date, B.order_date AS order_ date
CASE WHEN DATEDIFF(A.signup_date,B.order_date) <= 30 THEN 1
ELSE 0
END AS good_users
FROM users A
JOIN first_buyers B ON A.user_id = B.user_id
GROUP BY user_id)
SELECT A.user_id AS user_id,
AVG(DATEDIFF(A.signup_date,B.order_date)) AS avg_order,
C.category AS category
FROM 30_buyers A
JOIN order_items B ON A.order_id = B. order_id
JOIN items C ON B.item_id = C.item_id
WHERE A.good_users = 1
GROUP BY category
ORDER BY category, signup_date
틀린점 :
1. 30_buyers CTE절에서 user_id 쓰면 X
2. 문제에서 카테고리와 가입월 기준으로 정리하라했음 -> GROUP BY 에 추가
WITH first_buyers AS (
SELECT user_id, MIN(order_date) AS order_date
FROM orders
GROUP BY user_id),
30_buyers AS(
SELECT A.user_id AS user_id,
B.order_id AS order_id,
A.signup_date AS signup_date,
B.order_date AS order_date,
CASE WHEN DATEDIFF(A.signup_date,B.order_date) <= 30 THEN 1
ELSE 0
END AS good_users
FROM users A
JOIN first_buyers B ON A.user_id = B.user_id
GROUP BY user_id)
SELECT AVG(DATEDIFF(A.signup_date,A.order_date)) AS avg_order,
C.category AS category,
A.signup_date AS signup_date
FROM 30_buyers A
JOIN order_items B ON A.order_id = B.order_id
JOIN items C ON B.item_id = C.item_id
WHERE A.good_users = 1
GROUP BY category, signup_date
ORDER BY category, signup_date
🔹 문제 2: 장바구니 → 구매 퍼널 + 장바구니 미구매 이탈율 분석
테이블
- users(user_id, signup_date)
- events(user_id, event_type, event_date)
- event_type: 'add_to_cart', 'purchase'
- order_items(order_id, item_id, user_id, event_date)
- items(item_id, category)
요구사항
- 가입 후 30일 이내에 장바구니 추가한 유저 중,
- 장바구니 추가 후 14일 이내에 구매한 유저는 전환, 그렇지 않으면 이탈
- 각 상품 카테고리(category) 기준으로,
- 전환율(전환 유저 수 / 전체 장바구니 유저 수)
- 이탈율(이탈 유저 수 / 전체 장바구니 유저 수)
- 전체 유저 수
- 가입월 기준으로 정리
첫 풀이
WITH users AS (
SELECT DISTINCT A.user_id AS cartman,
MIN(A.signup_date) AS signup_date,
MIN(C.event_date) AS event_date
FROM users A
JOIN events B ON A.user_id = B.user_id
JOIN order_items C ON B.user_id = C.user_id
WHERE B.event_type = 'add_to_cart'),
30_buyers AS (
SELECT cartman, event_date, signup_date
CASE WHEN DATEDIFF(signup_date, event_date) <= 30 THEN 1
ELSE 0
END AS 30_buyers
FROM users),
convertion_users(
SELECT A.cartman AS cartman,
A.signup_date AS signup_date
,CASE WHEN DATEDIFF(A.event_date,B.event_date) <= 14 THEN 'convertion'
ELSE 'non_convertion'
END AS CONV
FROM 30_buyers A
JOIN events B ON A.user_id = B.user_id
WHERE B.event_type ='purchase')
SELECT (SELECT COUNT(CONV) FROM convertion_users WHERE CONV = 'convertion')/COUNT(cartman) AS convertion_rate,
(SELECT COUNT(CONV) FROM convertion_users WHERE CONV = 'non_convertion')/COUNT(cartman) AS non_convertion_rate,
MONTH(signup_date) AS signup_date,
(SELECT COUNT(DISTINCT user_id) FROM users) AS ALL_users
FROM convertion_users
GROUP BY signup_date문제:
맨처음 users-> C 조인할 필요없음 + event_date를 C가 아니라 B로 바꾸기
맨 마지막 -> users에서 cartman을 불러와야함 user_id가 아니라!
나머진 굿
🔹 문제 3 (난이도 ↑↑↑)
📌 테이블
- users(user_id, signup_date)
- logins(user_id, login_date)
- orders(order_id, user_id, order_date)
- order_items(order_id, item_id)
- items(item_id, category)
📌 요구사항
- 가입 월(Cohort) 기준 그룹화
- 각 유저가 가입 후 7일 이내에 재방문(로그인)했는지 여부 계산
- 7일 이내 재방문자 중 7일 이내 구매까지 한 유저 비율 계산
- 주문 시 포함된 상품의 카테고리 기준으로 결과 분리
- 최종 출력 컬럼
- signup_month
- category
- retention_rate (7일 이내 재방문자 / 전체 가입자)
- conversion_rate (7일 이내 재구매자 / 전체 가입자)
첫 풀이
WITH first_login AS (
SELECT A.user_id AS user_id,
A.signup_date AS signup_date,
MIN(B.login_date) AS login_date
FROM users A
JOIN logins B ON A.user_id = B.user_id
GROUP BY user_id),
7_days_visitors AS (
SELECT DISTINCT user_id AS user_id
,signup_date,
login_date,
CASE WHEN DATEDIFF(signup_date,login_date) <= 7 THEN 1 ELSE 0
END AS good_users
FROM first_login
),
order_users AS(
SELECT COUNT(A.user_id) AS total_signup,
MONTH(A.signup_date) AS signup_month,
SUM(A.good_users) AS 7_visitors,
CASE WHEN DATEDIFF(A.login_date, B.order_date) <= 7 THEN 1 ELSE 0
END AS 7_buyers
FROM 7_days_visitors A
JOIN orders B ON A.user_id = B.user_id)
SELECT A.signup_month AS signup_month,
C.category AS category,
(A.7_visitors / A.total_signup) AS retention_rate,
(SUM(A.7_buyers) / A.total_signup) AS conversion_rate
FROM order_users A
JOIN order_items B ON A.order_id = B.order_id
JOIN items C ON B.item_id = C.item_id
GROUP BY signup_month
틀린 점 ->
1. 마지막 GROUP BY -> SELECT한 카테고리도 포함해야함!
- MySQL은 기본적으로 SELECT 절에 있는 컬럼은 모두 GROUP BY에 있어야 함.
- 지금은 SELECT signup_month, category인데, category를 GROUP BY하지 않으면 에러 또는 비정의 집계 발생 가능.
2. 마지막 A.B 조인할 때 A에는 order_id없음
3. order_users에서 CASE WHEN 틀림 -> GROUP BY user_id로 묶어줘야함
-> GROUP BY user_id 아니면 SUM(CASE WHEN ...)
🔹 다음 문제: 카테고리별 Top 2 구매 유저 찾기
테이블
- orders(order_id, user_id, order_date)
- order_items(order_id, item_id)
- items(item_id, category)
요구사항
- 각 카테고리별로 가장 많이 구매한 유저 TOP 2를 구하세요
- 동점 시 모두 포함 (RANK 사용)
- 최종 출력: category, user_id, purchase_count, rank
🔹 문제: 카테고리별 Top 2 구매 유저 찾기 (RANK)
테이블
- orders(order_id, user_id, order_date)
- order_items(order_id, item_id)
- items(item_id, category)
요구사항
- 각 카테고리별로 가장 많이 구매한 유저 TOP 2를 구하세요
- 동점 시 모두 포함 (RANK 사용)
- 최종 출력: category, user_id, purchase_count, rank
WITH top2 AS (
SELECT A.user_id,
COUNT(*) AS purchase_count
,DENSE_RANK() OVER(PARRITION BY C.category ORDER BY COUNT(order_id) DESC) rk
FROM orders A
JOIN order_items B ON A.order_id = B.order_id
JOIN items C ON B.item_id = C.item_id
GROUP BY A.user_id, C.category
)
SELECT
B.category AS category,
A.user_id AS user_id,
A.purchase_count AS purchase_count,
A.rk AS rk
FROM top2 A
JOIN items B ON A.item_id = B.item_id
WHERE rank = 2
GROUP BY categoryPARTITION BY를 까먹었더니 아래처럼 답변해준다,,,,
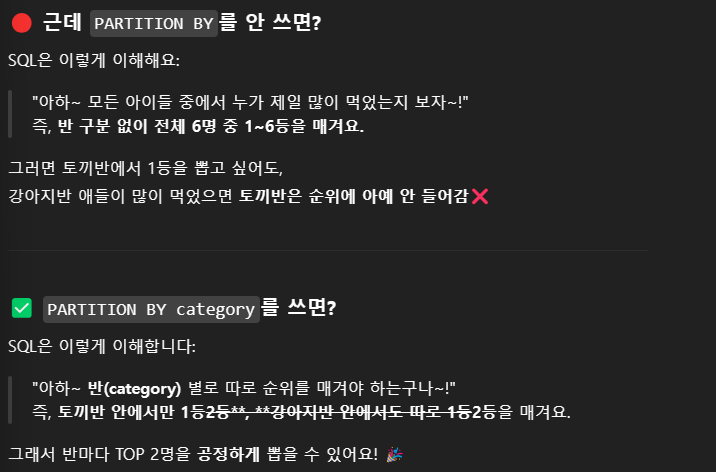
친절한 설명 고마워요
GROUP BY를 자꾸 틀려서 아래처럼 혼나버렸어요.
기본중에 기본인데 정신 똑바로 차리겠습니다
"GROUP BY는 줄 세우는 거고,
SELECT에 있는 애들은 줄 기준이거나, 줄에서 집계된 것만 써야 한다!"
그 외의 애가 SELECT에 들어오면 👉 "너 뭐냐?" 하면서 SQL이 화냅니다. 😡
이제 마지막 실전문제를 내달라고해봤다.
여러분들도 한 번 풀어보세요!
✴️ 실무형 A/B 테스트 + 리텐션 전환 분석 문제
💡 시나리오
당신은 마케팅팀 데이터 분석가입니다.
신규 유저를 대상으로 A/B 쿠폰 실험을 진행했고, 이후 가입 후 7일 이내에 접속한 유저를 리텐션 유저로 간주합니다.
실험 종료 후, 유저들이 어떤 상품 카테고리를 가장 많이 구매했는지,
그리고 A/B 그룹별로 리텐션된 유저 중 전환율이 높은 유저 상위 3명을 식별하는 것이 목표입니다.
📦 테이블 구조
📌 요구사항
다음 조건을 만족하는 SQL을 작성하시오:
- 가입 후 7일 이내 최소 1회 로그인한 유저를 리텐션 유저로 분류
- 리텐션 유저 중 상품을 1번이라도 구매한 유저만 대상
- 이들이 **어떤 카테고리(category)**를 가장 많이 구매했는지 확인 (카테고리별 구매 건수 집계)
- 그룹별(ab_group)로 전환율 상위 3명 유저 추출 (전환율 = 총 주문수 / 총 로그인수)
- RANK를 써서 A/B 그룹 내 전환율 Top 3 유저만 필터링
✅ 출력 예시
[1단계] 카테고리별 구매 건수 (리텐션 유저 한정)
| 의류 | 512 |
| 전자제품 | 421 |
| 식품 | 212 |
[2단계] 전환율 상위 3명 유저 (그룹별)
| A | u0123 | 4 | 3 | 0.75 | 1 |
| A | u0455 | 3 | 2 | 0.6667 | 2 |
| A | u0212 | 6 | 3 | 0.5 | 3 |
| B | u0345 | 2 | 2 | 1.0 | 1 |
| B | u0444 | 4 | 2 | 0.5 | 2 |
| B | u0111 | 6 | 3 | 0.5 | 2 |
단, 동점이면 같은 순위(DENSE_RANK), 최대 3명 이상 나올 수 있음
1단계)
WITH login AS (
SELECT A.user_id AS user_id,
A.signup_date AS signup_date,
MIN(B.login_date) AS login_date
FROM users A
JOIN logins B ON A.user_id = B.user_id
GROUP BY A.user_id, signup_date)
WITH retention AS (
SELECT C.category AS category,
COUNT(*) AS order_nums
FROM login A
JOIN orders B ON A.user_id = B.user_id
JOIN order_items OI ON B.order_id = OI.order_id
JOIN items C ON OI.item_id = C.item_id
WHERE DATEDIFF(A.signup_date,B.login_date) <= 7
GROUP BY C.category)
2단계)
WITH login AS (
SELECT A.user_id AS user_id,
A.signup_date AS signup_date,
A.ab_group AS ab_group,
MIN(B.login_date) AS login_date,
COUNT(B.login_date) AS total_login
FROM users A
JOIN logins B ON A.user_id = B.user_id
GROUP BY A.user_id, A.signup_date, A.ab_group),
retention AS (
SELECT A.ab_group AS ab_group,
A.user_id AS user_id,
COUNT(B.order_id) AS total_order,
A.total_login AS total_login
JOIN orders B ON A.user_id = B.user_id
JOIN order_items OI ON B.order_id = OI.order_id
JOIN items C ON OI.item_id = C.item_id
WHERE DATEDIFF(A.signup_date,B.login_date) <= 7
GROUP BY A.ab_group , A.user_id),
convertion AS(
SELECT user_id,
ab_group,
total_login,
total_order,
(total_login/total_order) AS convertion_rate,
DENSE_RANK() OVER(PARTITION BY ab_group ORDER BY (total_order/total_login) DESC) rank
FROM retention
GROUP BY ab_group, user_id)
SELECT *
FROM convertion
WHERE rank = 3'SQLD' 카테고리의 다른 글
| SQL 8일차 (0) | 2025.05.02 |
|---|---|
| SQL 7일차 (0) | 2025.05.01 |
| SQL 6일차 #SQL 키트 + GPT 문제 (1) | 2025.05.01 |
| SQL 5일차 #LeetCodE (0) | 2025.04.27 |
| SQL 3일차 #프로그래머스 (0) | 2025.04.24 |