딥러닝: 머신러닝의 한 종류로, 데이터 처리 유닛의 층을 여러 개 쌓아 구조적이지 않은 데이터에서 고수준 표현을 학습!
2.1 데이터
일반적으로 머신러닝에서 사용되는 정형 데이터이다.
정형 데이터: 양적 데이터, 사전에 정의됨(유연하지 않음). 분석이 상대적으로 쉬움
비정형 데이터: 질적 데이터, 특정 스키마(DB를 구성하는 요소들의 관계)가 포함되어 있지 않다. 유연함, 분석 어려움
구체적으로, 비정형 데이터는 이미지/오디오/텍스트와 같이 태생적으로 특성의 열로 구성할 수 없는 것들을 말한다.

픽셀/진동 수/문자 하나하나에는 정보가 거의 없다. 예를 들어 이미지의 234번 째의 픽셀이 황토색이라는 정보는 의미는 도움이 되지 않는다는 뜻이다.
물론 딥러닝에서 정형데이터를 사용하면 안되는 것은 아니지만, 딥러닝의 강력함은 비정형 데이터를 다루는 것에서 나온다는 것이다.
2.2 심층 신경망
딥러닝 여러 개의 은닉층을 쌓은 인공 신경망(ANN(Artificial Neural Network)이다.
따라서 심층 신경망(DNN(Deep Neural Network)와 동의어로 쓰이곤 한다.
2.2.1 신경망이란?
심층 신경망은 층을 연속하여 쌓아 만든다. 각 층은 유닛을 가지며, 이전 층의 유닛과는 가중치로 연결된다.
"층"은 종류가 많으며, 보통 모든 유닛 이전 층의 모든 유닛과 연결되는 완전 연결층이 있다.(밀집 층이라고함)
다층 퍼셉트론 (MLP(multilayer perception)
-인접한 모든 층이 완전하게 연결된 신경망
2.2.2 고수준 특성 학습
신경망의 최대 장점은 사람의 개입 없이도 데이터를 스스로 학습하는 능력이라고 할 수 있다.
즉, 특성 공학(feature engineering)을 수행할 필요가 없다는 것.
(예측 오차를 줄이기 위해 가중치를 어떻게 조정할 지를 모델이 결정)
아래 텍스트 그림을 살펴보자.
2.3.1 예제 학습
keras에서 제공하는 CIFAR-10 데이터 셋을 이용하여 학습을 진행해보자.
여기서 만약 x_train 데이터에서 54번째 사진에서, 픽셀 12,13에 위치해 있는 RGB 값을 보고 싶다면?

슬라이싱!
이제 텐서 라이브러리를 이용해서 다층 퍼셉트론을 만들어보자.
방법1)

방법2)

방법1과 방법2 중 어떤것이 나을까?
지금 예제 실습에서는 상관없지만, 보통 2번의 방식을 선호한다고 한다.
방법1은 층 별로 직접 변수를 설정했지만, 나중에 수 백 수 천개의 층을 만들기에는 적합하지 않을 수 있다.
따라서 함수 API를 불러오는 방법2의 방식을 사용하도록 하자!
참고로 방법 1,2 모두 아래 그림을 프로그래밍한것과 같다.

위 코드 & 그림을 보면 알 수 있듯이 층의 종류는 총 세 가지 임을 확인할 수 있다.
Input, Flatten, Dense층이다. 세 가지 모두 자세히 알아보도록 하자.
Input 층
- 네트워크의 시작점이라고 할 수 있다. 여기서 입력 데이터의 배치 크기는 필요하지 않기 때문에 배치 크기는 지정하지 않는다. 여기서 배치 크기는 50,000.
그 다음 Flatten 층은 이름처럼 하나의 벡터로 펼친다. 이렇게 되면 (32x32x3 = 3,072가 되겠다.)
Flatten을 하는 이유는 뒤에 따르는 Dense 층에서 받는 배열이 1차원이기 때문이다.
(다른 종류의 층은 Flat한 층이 아닌 다차원 배열을 입력으로 받는다는 점 주의)
Dense 층
-기본적인 신경망 구성요소.
1. Dense층의 각 유닛은 이전 층의 모든 유닛들과 완전 연결된다. +모든 연결마다 가중치가 동반
2. 유닛의 출력은 이전 층에서 넘겨받은 입력과 가중치의 곱들을 모두 더하여 구함.
3. 그 다음 비선형 활성화 함수에 전달
활성화 함수
- 퍼셉트론의 출력값을 결정하는 비선형 함수
- 대표적으로 렐루, 시그모이드, 소프트맥스 함수가 있음
렐루: 음수면 0, 양수면 그 값 그대
리키렐루: 양수일 경우는 렐루와 같지만, 음수일 경우 0이 아닌 값에 비례한 작은 음수값을 반환함
기존렐루의 경우 모두 0이면 그라디언트 값이 0이되어 학습진행에 차질이 있을 수 있기 때문
시그모이드: 출력값이 0~1. (이진 분류 / 다중 레이블 분류시 사용가능)

소프트맥스: 층의 전체 출력값들의 합이 1 (다중 분류 시 용이)

모델 검사하기
-model.summary()를 사용해 각 층을 조사할 수 있다.

Input층의 크기는 x_train의 크기와 같아야 하고, Dense층의 크기는 y_train의 크기와 같아야 한다.(???)
Input 층에서, None이 나오는데, 이는 위에서 언급했듯이, 배치 크기는 필요없기 때문.
텐서플로우의 연산 방식은 선형 대수학을 이용, 입력된 샘플(n개)상관없이 동시에 수행하기 때문이다.
(GPU가 중요한 이유, GPU는 텐서 곱셈에 최적)
파라미터 개수
Dense#1층 = 32x32x3 + 200(Dense층의 bias(상수)) = 614,600개
Dense#2층 = (200x150) + 150 = 30,150개
Dense#3층 = (150x10) + 10 = 1,510개
2.3.2 모델 컴파일
- 모델 컴파일은 손실 함수 & 옵티마이저를 이용
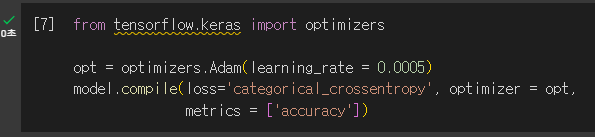
손실 함수
손실 함수의 결과값은 모델의 예측값과 정답값의 차이를 통해 구한다. (결과가 크면 bad)
대표적으로 MSE, 범주형 크로스 엔트로피(categorical), 이진 크로스 엔트로피(binary)가 있다.
회귀 -> MSE / MAPE / SMAPE 등
다중 분류 -> 범주형 크로스 엔트로피 (categorical cross-entropy)
이진 분류 -> 이진 크로스 엔트로피 (binary cross-entropy)
옵티마이저
손실 함수 그레디언트를 기반으로 신경망의 가중치를 갱신할 때 사용함.
Adam / Adagrid / RMSprop / Momentum / SGD 등등 (일반적으로는 Adam 사용)
2.4 모델 훈련 & 평가


2.5 합성곱 신경망
위의 결과값을 보면 알겠지만 정확도가 아주 처참하다.!
이 이유는 입력 이미지의 공간 구조를 잘 다루지 못했기 때문이다. (무지성 Flatten으로 갈겼기 때문)
2.5.1 합성곱 층

위 설명을 참조하게 되면, 이미지 영역이 필터와 비슷할 수록 큰 양수, 반대일 수록 큰 음수가 출력되는 것이다.

직접 코드를 짜보자.

스트라이드: 도장(필터)의 이동 간격!
패딩: 제로패딩 등 특정 값으로 채워넣는것, 크기를 맞춰주기 위한 용도라고 보면 된다.
정확히는 입력 배열의 주위를 가상의 원소로 채우는 작업이라고 할 수 있다.
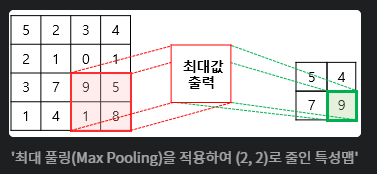
풀링: 맥스풀링 등 아래 그림을 통해 이해! (축소시킨다는 개념)
직접 합성곱의 층을 쌓아보자

그림으로 이해해보면 아래와 같다.

'딥 러닝 > 생성형 AI' 카테고리의 다른 글
| 05. 확산 모델 (Diffusion model) (0) | 2024.05.31 |
|---|---|
| 04. 적대적 생성 신경망(GAN) (0) | 2024.04.06 |
| 03. 변이형 오토인코더 (2) | 2024.03.22 |
| 01. 생성 모델 (2) | 2024.03.11 |